10 инструментов, которые помогут найти удалённую страницу или сайт
Содержание:
- Анализ поисковых запросов сайта
- Как найти нужный веб-архив и восстановить сайт без бекапа
- Reasons for using the Wayback Downloader
- Блокировка Архива Интернета[ | код]
- Обновление виджета на Smart TV
- 1944
- What Is Wayback Machine
- FAQs About Web Archive
- mydrop.io
- Что делать, если удалённая страница не сохранена ни в одном из архивов?
- 1972
- Поиск сайтов в Wayback Machine
- HTML верстка и анализ содержания сайта
- r-tools.org
- Юридические проблемы с архивным контентом
- Archive.is
- Примечания
- archive.md
- 1997
- 1912
Анализ поисковых запросов сайта
Приведённый выше отчёт по частотности использования поисковых запросов, может быть использован оптимизаторами сайта при составлении его семантического ядра и подготовке контента т.н. «посадочных страниц». Статистика поисковых запросов — обобщённая сгруппированная информация по «обращениям» пользователей к поисковой системе по ключевым запросам (фразам).
В большинстве случаев, наш сервис показывает уже сгруппированную информацию, содержащую не только подборку самых популярных слов (фраз), но и словосочетания + синонимы. Собранная в данном разделе статистика показывает по каким «ключевым словам» (поисковым запросам) пользователи переходят на сайт waybackmachine.org.
Поисковый запрос – это слово или словосочетание, которое пользователь вводит в форму поиска на сайте поисковой системы, с учётом автоподбора и автоматического исправления в поиске ошибочного набора.
Как найти нужный веб-архив и восстановить сайт без бекапа
По архивам можно перемещаться и с помощью временной шкалы расположенной вверху страницы, где вертикальными черными черточками отмечены имеющиеся для этого сайта слепки. Иногда, веб-архивы могут быть битыми, тогда придется открыть ближайший к нему слепок.
Щелкнув по голубому кружочку мы можем увидеть ссылки на несколько архивов, отличающихся временем их снятия.
Возможно, что это делается во избежании потери данных за счет неизбежной порчи жестких дисков в хранилищах. Перейдя к просмотру одного из веб-архивов, вы увидите копию своего (в данном примере моего) сайта с работающими внутренними ссылками и подключенным стилевым оформлением. Правда, не идеально работающим.
Например, кое-что из дизайна у меня все же перекосило и боковое меню работающее на ДжаваСкрипте полностью исчезло:
Но это не столь важно, ибо в исходном коде страницы с web.archive.org это меню, естественно, присутствует. Однако, просто так скопировать текст этой страницы к себе на сайт взамен утерянной не получится
Почему? Да потому что путешествие внутри сайта из прошлого будет возможно лишь в случае замены всех внутренних ссылок на те, что генерит Webarchive (в противном случае вас перебросило бы на современную версию ресурса).
Выглядят эти ссылки примерно так:
http://web.archive.org/web/20111013120145/https://ktonanovenkogo.ru/seo/search/samostoyatelnoe-prodvizhenie-sajta-kak-prodvigat-samomu-vnutrennej-optimizaciej.html
Понятно, что можно будет вручную отсечь вступительную часть ссылок (), получив таким образом рабочий вариант. Можно этот процесс даже автоматизировать с помощью инструмента поиска и замены редактора Notepad, но еще проще будет воспользоваться встроенной в этот сервис возможностью замены внутренних ссылок на оригинальные.
Для этого копируете адрес страницы с нужным слепком вашего сайта (из адресной строки браузера — начинается с ). Он будет иметь примерно такой вид:
http://web.archive.org/web/20111013120145/https://ktonanovenkogo.ru/
И вставляете в него конструкцию «id_» в конце даты (), чтобы получилось так:
http://web.archive.org/web/20111013120145id_/https://ktonanovenkogo.ru/
Теперь измененный адрес обратно возвращаете в адресную строку браузера и жмете на Enter. После этого страница c архивом вашего сайта обновится и все внутренние ссылки станут прямыми. Можно будет копировать текст статьи из исходного кода вебархива.
Понятно, что восстановление таким образом огромного сайта займет чудовищное количество времени, но когда другого варианта нет, то и такой покажется манной небесной. К тому же, страдают невозвратной потерей контента обычно только начинающие вебмастера, у которых этого самого контента было мало, а более-менее опытные сайтовладельцы, уж не раз обжигавшиеся на подобных вещах, делают бэкапы файлов и базы по пять раз на дню.
Если вы захотите увидеть все страницы вашего (или чужого) сайта, которые содержатся в недрах этого мастодонта, то вам нужно будет вставить в адресную строку браузера следующий адрес и нажать Enter:
http://wayback.archive.org/web/*/ktonanovenkogo.ru*
Вместо моего домена можно использовать свой. На открывшейся странице вы получите возможность наложить фильтр в предназначенной для этого форме:
Например, я захотел увидеть лишь текстовые файлы своего блога, которые заглотил Web Archive. Зачем — не знаю, но захотел.
Reasons for using the Wayback Downloader
What possible reasons can you have to download sites from the Wayback Machine?
- Missed hosting payments. Let’s say you’re super responsible webmaster. You always update and keep fresh content. You do security updates. You’re on top of things. But one day, you visit your website and all your content is gone! It’s in this moment that you remember that you forgot to change that credit card that was linked to your hosting account. Now all your content is gone! Dashed away by one false move..or is it? Enter our web Archive download bot. With a few simple clicks, you can be on your way to restoring a whole website — exactly like it used to be.
- Nostalgia. Maybe you played a computer game as a teenager or you used to frequently visit some hobby website. Many of these websites change or go offline, but with an archive.org download order, you can recover all your nostalgic memories.Simply go to our wayback machine download site and create your own web.archive.org download. This includes your whole website, up to 10 levels deep, which means all pages that are 10 clicks away from the front page.
- Your site was hacked. What if a more sinister plot involving a hacker compromising the security of your site arises? He’s hijacked your site, and now all your content has been deleted and replaced with ads for his own benefit. Not to worry! We have you covered with a nice Wayback machine download of your website, as it was before disaster struck.
- Legal evidence. Should you ever find yourself embroiled in a legal battle over whatever the issue may be, The Wayback Downloader can help here too. Make a copy of the web archive data for use as evidence in lawsuits. For example, patent law and evidence of prior art. The Wayback Machine accepts removal requests, so it’s a good idea to have your own copy in case the website disappears from the web archive.
- Internet Marketeers. Another neat feature of the Wayback Machine Downloader is the ability to recover content from a site that you may have purchased for purposes of SEO. Got a new PBN site that you want to revamp to include the old content it used to contain and maintain Google’s trust? The Wayback Machine Downloader steps in here and makes a seamless transition to the way the site was before.
- Take content from a bankrupt competitor. What if one of your biggest competitors has gone out of business, and with their exit from the business they also took down their website? Remember the URL? Voila! You’ve got yourself a ton of useable information to populate your new site with one less competitor to worry about. Basically, this can be for any site in your industry that was taken offline.
- For recovering expired content Sometimes you have good expired content — perhaps you found it with our service or with software like the Expired Article Hunter. Let’s say you have a good PBN domain with high metrics, and you have another domain with good expired content. Now you can merge the two domains and rebuilding the expired content on the domain with high metrics. It’s one of the quickest and best methods to build a PBN
- Use it as an alternative to httrack. Httrack is software to scrape live websites, but it doesn’t do a very good job at scraping the internet archive. We rebuild websites as they once were, while httrack simply copies a complete site, including all the headers and archive URLs
As you can see there are plenty of reasons to use the Wayback Machine Downloader. It is the perfect solution to download site from wayback machine. If you need help with any of the above, don’t hesitate to send us a message. We are glad to help you out.
Блокировка Архива Интернета[ | код]
В России | код
| Внешние изображения |
|---|
В октябре 2014 года Роскомнадзор заблокировал на территории РФ доступ к некоторым страницам Архива Интернета за видеоролик «Звон мечей» экстремистской группировки «Исламское государство Ирака и Леванта» (нынешнее название — «Исламское государство»). Ранее блокировались только ссылки на отдельные материалы в архиве, однако 24 октября 2014 года в реестр запрещённых сайтов временно был включён сам домен и его IP-адрес.
16 июня 2015 года на основании статьи 15.3 закона «Об информации, информационных технологиях и о защите информации» генпрокуратура РФ приняла решение о блокировке страницы «Одиночный джихад в России», содержащей, по её мнению, «призывы к массовым беспорядкам, осуществлению экстремистской деятельности, участию в массовых мероприятиях, проводимых с нарушением установленного порядка», в действительности на территории России был заблокирован доступ ко всему сайту, кроме .
С апреля 2016 года Роскомнадзор решил убрать сайт из блокировок, и он доступен в России.
По состоянию на 22 августа 2019 года в Мосгорсуде находятся на рассмотрении иски Ассоциации по защите авторских прав в интернете (АЗАПИ), в которых заявлено требование о блокировке интернет-портала archive.org на территории России в связи с нарушениями авторских прав.
В других странах СНГ | код
Архив блокировался на территории Казахстана в 2015 году.
Также в 2017 году сообщалось о блокировках архива в Киргизии.
В Индии | код
В Индии Архив был частично заблокирован судебным решением в августе 2017 года. Решение Madras High Court перечисляло 2,6 тыс. адресов в сети Интернет, которые способствовали пиратскому распространению ряда фильмов двух местных кинокомпаний. Представители проекта безуспешно пытались связаться с министерствами.
Обновление виджета на Smart TV
Для обновления нужно зайти в настройки аккаунта и выбрать пункт «Версия ПО». Там же можно проверить наличие обновлений и загрузить недостающие компоненты. Обновить можно и таким способом: удалить прошлую версию и установить новую с флешки.
ForkPlayer установка с флешки:
- Перейдите на главный экран.
- Найдите там пакет управления ForkPlayer.
- Активируйте и перейдите в личный кабинет.
- В настройках программы нужно пролистать список в самый низ и выбрать «Деинсталляция».
- После нажатия пункта и подтверждения, программа удалится.
- Затем нужно перезагрузить ТВ, но с уже вставленной флешкой.
- Инструкция по установке с флешки описана выше.
Теперь когда мы разобрали как установить программу с флешки и как удалить ForkPlayer с телевизора Samsung, рассмотрим проблемы и способы решения.
1944
Sab Masada
The Time Machine cranked to 1944, out came Rick Prelinger, Internet Archive Board member, archivist, and filmmaker. Prelinger introduced a new addition to the Internet Archive’s film collection: long-forgotten footage of an Arkansas Japanese internment camp from 1944. As the film played on the screen, Prelinger welcomed Sab Masada, 87, who lived at this very camp as a 12-year-old.
Masada talked about his experience at the camp and why it is important for people today to remember it. “Since the election I’ve heard echoes of what I heard in 1942,” Masada said. “Using fear of terrorism to target the Muslims and people south of the border.”
What Is Wayback Machine
Wayback machine is among the best websites for internet archiving which millions of people use every day. To create strategic plans and evaluate their rivals, many companies rely on it. It allows us to see an indexed web site’s history and how it was created.
There can be various uses of it, some of which include learning the progress of rivals, finding lost information, and viewing down-website content. It is vital to have access to the Wayback machine all the time since it is often used in crucial scenarios. Sadly, no one can completely guarantee that a website won’t ever be down. Therefore, you need to be prepared for this.
If the Wayback machine is down, then you can look for other Internet Time Machine website. You may even want to get your hands on something new with a few different functionalities from the Wayback Machine.
In this article, we will review the top 10 Wayback Machine Alternatives. We will go through the pros, features, and pricing of each alternative to help you decide which is the best option for your particular situation and budget. Before we get to the comparison/review of the alternatives, we will do a quick fact check related to the Wayback machine and its alternatives.
Fact Check: The Wayback Machine is touted as the best website for internet archiving, with millions of people using it each day for different purposes. An internet-based website, the Wayback Machine is a non-profit application that enables us to find out what a specific site looked like through the years—from 1996 to the present day. Going back as far as 1996, the Wayback machine has collated over 424 billion web pages.
Illustration of the number of web pages cataloged by Wayback Machine Internet Archive:
Pro Tip: When choosing an internet archive website, always pick an option that suits your intent or what you want to achieve from this exercise. If you’re not sure about this, then listen to what the experts are saying. According to most experts who have reviewed the different archive sites, the best internet archive alternatives to Wayback machines today are archive.today and Pagefreezer.
Although these are sound recommendations, we would suggest you go through all the alternatives reviewed in this article to find the best ones for your particular situation rather than blindly choosing archive.today or Pagefreezer based on expert opinion. This will do you good!
FAQs About Web Archive
Q #1) How many types of alternatives to Wayback Machine are there?
Answer: The Wayback machine has two types of alternative sites. The first is a support community that helps you to browse through any past website. An example of this type of website is archive.today. With the other type of alternatives, you can create a private ‘Wayback machine’ for different domains. Pagefreezer is an example of this type.
Q #2) How do I access archived websites?
Answer: Archived websites can be accessed through the Wayback Machine or alternative web archive sites using any tablet, smartphone, or laptop. Simply navigate to the website in your browser and search for the archived websites to view them.
Q #3) Is web archive legitimate?
Answer: The Wayback machine and its alternatives are legitimate non-profit repositories of old websites and pages that have archived for long.
=> Contact us to suggest your listing here.
mydrop.io
(реф. ссылка)
Удобный сервис, кроме фнкционала восстановления контента сайта имеет фунционал поиска доменов по различным параметрам. Пользуюсь им больше года.
Из преимуществ:
- широкий набор фильтров для поиска домена
- возможность подписки на фильтр
- информативная таблица доменов с полезными seo метрикам( TF, CF, DA, PA, LinkPad, SimilarWeb, LiveInternet, Alexa)
- показывают кол-во файлов, которые восстановить и размер в МБ
- показывают, есть ли ставки на домен через сервис expired.ru
- Есть своя Cms
- адекватные цены
- скидки при пополнении счета от 3000 руб.
- интерфейс на русском
Из минусов:
- нет пробного периода либо бесплатного восстановления, если восстонавливаемый сайт «небольшой»
- есть функционал предварительного просмотра, но он очень сыроват и на счета должна быть сумма не меньше чем стоимость восстановления
Что делать, если удалённая страница не сохранена ни в одном из архивов?
Архивы Интернета сохраняют страницы только если какой-то пользователь сделал на это запрос — они не имеют функции обходчиков и ищут новые страницы и ссылки. По этой причине возможно, что интересующая вас страница оказалась удалено до того, как была сохранена в каком-либо веб-архиве.
Тем не менее можно воспользоваться услугами поисковых движков, которые активно ищут новые ссылки и оперативно сохраняют новые страницы. Для показа страницы из кэша Google нужно в поиске Гугла ввести
cache:URL
Например:
cache:https://hackware.ru/?p=6045
Если ввести подобный запрос в поиск Google, то сразу будет открыта страница из кэша.
Для просмотра текстовой версии можно использовать ссылку вида:
http://webcache.googleusercontent.com/search?q=cache:URL&strip=1&vwsrc=0
Для просмотра исходного кода веб страницы из кэша Google используйте ссылку вида:
http://webcache.googleusercontent.com/search?q=cache:URL&strip=0&vwsrc=1
Например, текстовый вид:
http://webcache.googleusercontent.com/search?q=cache:https://hackware.ru/?p=6045&strip=1&vwsrc=0
Исходный код:
http://webcache.googleusercontent.com/search?q=cache:https://hackware.ru/?p=6045&strip=0&vwsrc=1
1972
Next to speak was Wendy Hanamura, the director of partnerships. Hanamura explained how as a sixth grader she discovered a book at the library, Executive Order 9066, published in 1972, which chronicled photos of Japanese internment camps during World War II.
“Before I was an internet archivist, I was a daughter and granddaughter of American citizens who were locked up behind barbed wire in the same kind of camps that incarcerated Sab,” said Hanamura. That one book – now out of print – helped her understand what had happened to her family.
Inspired by making it to the semi-final round of the MacArthur 100&Change initiative with a proposal that provides libraries and learners with free digital access to four million books, the Internet Archive is forging ahead with plans, despite not winning the $100 million grant. Among the books the Internet Archive is making available: Executive Order 9066.
Поиск сайтов в Wayback Machine
Wayback Machine
На странице «Internet Archive Wayback Machine» введите в поле поиска URL адрес сайта, а затем нажмите на кнопку «BROWSE HISTORY».
Под полем поиска находится информация об общем количестве созданных архивов для данного сайта за определенный период времени. На шкале времени по годам отображено количество сделанных архивов сайта (снимков сайта может быть много, или, наоборот, мало).
Выделите год, в центральной части страницы находится календарь, в котором выделены голубым цветом даты, когда создавались архивы сайта. Далее нажмите на нужную дату.
Вам также может быть интересно:
- Советские фильмы онлайн в интернете
- Яндекс Дзен — лента персональных рекомендаций
Обратите внимание на то, что при подведении курсора мыши отобразится время создания снимка. Если снимков несколько, вы можете открыть любой из архивов
Сайт будет открыт в том состоянии, которое у него было на момент создания архива.
За время существования моего сайта, у него было только два шаблона (темы оформления). На этом изображении вы можете увидеть, как выглядел мой сайт в первой теме оформления.
На этом изображении вы видите сайт моего знакомого, Алема из Казахстана. Данного сайта уже давно нет в интернете, поисковые системы не обнаруживают этот сайт, но благодаря архиву интернета все желающие могут получить доступ к содержимому удаленного сайта.
HTML верстка и анализ содержания сайта
Размещённая в данном блоке информация используется оптимизаторами для контроля наполнения контентом главной страницы сайта, количества ссылок, фреймов, графических элементов, объёма теста, определения «тошноты» страницы.
Отчёт содержит анализ использования Flash-элементов, позволяет контролировать использование на сайте разметки (микроформатов и Doctype).
IFrame – это плавающие фреймы, которые находится внутри обычного документа, они позволяет загружать в область заданных размеров любые другие независимые документы.
Flash — это мультимедийная платформа компании для создания веб-приложений или мультимедийных презентаций. Широко используется для создания рекламных баннеров, анимации, игр, а также воспроизведения на веб-страницах видео- и аудиозаписей.
Микроформат — это способ семантической разметки сведений о разнообразных сущностях (событиях, организациях, людях, товарах и так далее) на веб-страницах с использованием стандартных элементов языка HTML (или XHTML).
r-tools.org
Первое, что бросается в глаза дизайн сайта стороват. Ребята, пора обновлять!
Плюсы:
- Подходит для парсинга сайтов у которых мало html страниц и много ресурсов другого типа. Потомучто они рассчитывают цену по html страницам
- возможность отказаться от сайта, если качество не устроило. После того как система скачала сайт, вы можете сделать предпросмотр и отказаться если качество не устроило, но только если еще не заказали генерацию архива. (Не проверял эту функцию лично, и не могу сказать на сколько хорошо реализован предпросмотр, но в теории это плюс)
- Внедрена быстрая интеграция сайта с биржей SAPE
- Интерфейс на русском языке
Минусы:
- Есть демо-доступ — это плюс, но я попробовал сделать 4 задания и не получил никакого результата.
- Высокие цены. Парсинг 25000 стр. обойдется в 2475 руб. , а например на Архивариксе 17$. Нужно учесть, что r-tools считает html страницы, архиварикс файлы. Но даже если из всех файлов за 17$ только половина html страницы, все равно у r-tools выходит дороже. (нужно оговориться, что считал при $=70руб. И возможна ситуация, когда r-tools будет выгоден написал про это в плюсах)
Юридические проблемы с архивным контентом
Против Internet Archive было возбуждено несколько дел за его усилия по архивированию Wayback Machine.
Саентология
В конце 2002 года Интернет-архив удалил из Wayback Machine различные сайты, критикующие Саентологию . В сообщении об ошибке говорилось, что это было ответом на «запрос владельца сайта». Позже выяснилось, что юристы Церкви Саентологии требовали удаления и что владельцы сайта не хотели, чтобы их материалы были удалены.
Healthcare Advocates, Inc.
В 2003 году компания Harding Earley Follmer & Frailey защитила клиента от спора о товарных знаках с помощью Archive’s Wayback Machine. Адвокаты смогли продемонстрировать, что требования истца были недействительными, основываясь на содержании их веб-сайтов за несколько лет до этого. Затем истец, Healthcare Advocates, изменил свою жалобу, включив в нее Интернет-архив, обвинив организацию в нарушении авторских прав, а также в нарушениях Закона США » Об авторском праве в цифровую эпоху» и Закона о компьютерном мошенничестве и злоупотреблениях . Healthcare Advocates утверждали, что, поскольку они установили файл robots.txt на своем веб-сайте, даже если после подачи первоначального иска Архив должен был удалить все предыдущие копии веб-сайта истца с Wayback Machine, однако некоторые материалы продолжали оставаться быть общедоступным на Wayback. Иск был урегулирован во внесудебном порядке после того, как Wayback устранил проблему.
Сюзанна Шелл
Активист Suzanne Shell подал иск в декабре 2005 года, потребовав Internet Archive платить 100000 $ HER США для архивирования ее сайта profane-justice.org в период между 1999 и 2004 Internet Archive подал декларативное суждение иска в окружном суде Соединенных Штатов для северного округа Калифорнии на 20 января 2006 г., добиваясь судебного определения, что Интернет-архив не нарушает авторские права Shell . Shell отреагировала и подала встречный иск против Internet Archive за архивирование ее сайта, которое, как она утверждает, нарушает ее условия обслуживания . 13 февраля 2007 г. судья Окружного суда США округа Колорадо отклонил все встречные иски, за исключением нарушения контракта . Интернет-архив не стал отклонять иски Shell о нарушении авторских прав, связанные с ее копировальной деятельностью, которые также будут проданы.
25 апреля 2007 г. Internet Archive и Сюзанна Шелл совместно объявили об урегулировании своего иска. Интернет-архив сообщил, что «… не заинтересован во включении в Wayback Machine материалов лиц, которые не желают архивировать свой веб-контент. Мы признаем, что г-жа Шелл имеет действующие и подлежащие исполнению авторские права на свой веб-сайт, и мы сожалеем что включение ее веб-сайта в Wayback Machine привело к судебному разбирательству «. Shell заявила: «Я уважаю историческую ценность цели Internet Archive. Я никогда не намеревался мешать достижению этой цели или причинять ей какой-либо вред».
Даниил Давыдюк
В период с 2013 по 2016 году порнографический актера по имени Daniel Davydiuk пытался удалить заархивированные образа себя из архива Wayback Machine, сначала отправив несколько запросов DMCA в архив, а затем, обратившись к Федеральному суду Канады .
Archive.is
Archive.is является еще одной хорошей альтернативой Wayback Machine и, возможно, лучше, чем скриншоты для большинства людей. Это не один из самых привлекательных веб-сайтов или простой в навигации, но его база данных и методы архивирования восполняют его.
Archive.is позволит вам выполнять поиск по истории веб-сайта и снимать скриншот любого домена по запросу, который будет сохранен для всеобщего просмотра. Это делает его идеальным решением для получения всех подробностей о веб-сайте, включая данные и графические данные.
Как это устроено
Archive.is архивирует веб-сайт по запросу или в соответствии с частотой действий на конкретном веб-сайте. Это займет и скриншот и код сайта во время архивирования. Однако, в отличие от Wayback Machine, он не отправляет сканеры для архивирования веб-страниц. Это означает, что веб-сайт не может остановить Archive.is от архивирования с использованием файла robot.txt.
Если существует веб-сайт, который может блокировать сканирование Wayback Machine своего сайта, вам следует выбрать Archive.is, чтобы получить доступ к нему.
Практическое использование
Веб-сайт Archive.is не так привлекателен, как Wayback Machine или Screenshots. Хотя, это довольно просто для навигации с наименьшим количеством вариантов для беспокойства. На главной странице вы найдете две панели поиска, одну красную сверху и другую синюю снизу. Красная панель поиска — это место, где вы можете запросить архивирование веб-страницы, а синим цветом вы можете просмотреть историю любого веб-сайта.
Архив спроса
В красной строке поиска вы можете потребовать архивирование любого веб-сайта, а Archive.is скопирует код и сделает его снимок экрана. Просто введите URL-адрес страницы веб-сайта в строку поиска и нажмите «сохранить страницу».
Archive.is начнет обработку и после небольшой задержки (в зависимости от размера страницы) вы увидите заархивированную страницу и снимок экрана с ней.
Примечание . Вы не ограничены простым добавлением URL-адреса целевой страницы определенного веб-сайта, вы можете добавить URL-адрес любой страницы веб-сайта. Просто зайдите на страницу, которую вы хотите заархивировать, и скопируйте / вставьте ее URL в архиве. При поиске он будет заархивирован.
Проверить архивную историю веб-сайта
В синей строке поиска ниже вы можете ввести URL-адрес веб-сайта, и вы увидите всю его историю. Будет два варианта: самый старый и самый новый. Самая старая содержит самую старую заархивированную веб-страницу, а самая новая содержит самые последние заархивированные страницы и возвращаясь оттуда.
Вы увидите все заархивированные страницы, начиная с самых последних и возвращаясь назад, вместе с данными, указанными под каждой веб-страницей. Вы можете просто нажать на любую веб-страницу, чтобы увидеть ее детали.
Откроется архивированная веб-страница, и вы можете легко перемещаться по ней. Вы можете нажать на «Снимок экрана», чтобы увидеть скриншот этой конкретной веб-страницы.
В наших результатах скриншоты архивировались 9gag 21 раз, а с другой стороны, Archive.is архивировал его 1063 раза. С этим небольшим примером вы можете взвесить частоту архивирования сайта.
Основные характеристики: архивирует как код, так и снимок экрана веб-страницы, огромную базу данных, обменивается результатами и загружает их, а также запрашивает архивирование любого веб-сайта в любое время.
Минусы: непривлекательный интерфейс, сложно ориентироваться на нужной веб-странице и не предоставляет много информации о конкретной веб-странице.
Примечания
-
(англ.). Alexa Internet. — Глобальный рейтинг сайта archive.org. Дата обращения: 20 июня 2020.
- .
- .
- (англ.). archive.org. Дата обращения: 28 марта 2019.
- . Internet Archive (7 мая 2007). Дата обращения: 31 августа 2016.
- (недоступная ссылка). Wayback Machine (6 июня 2000). Дата обращения: 1 сентября 2016.
- Jeff. (Blog). Wayback Machine Forum. Internet Archive (23 сентября 2002). Дата обращения: 4 января 2007. Author and Date indicate initiation of forum thread
- Miller, Ernest (Blog). LawMeme. Yale Law School (24 сентября). Дата обращения: 4 января 2007. The posting is billed as a ‘feature’ and lacks an associated year designation; comments by other contributors appear after the ‘feature’
- Maximillian Dornseif. (англ.). preprint cs/0404005 16. arXiv (2004). Дата обращения: 26 ноября 2017.
- .
- .
- (недоступная ссылка). Дата обращения: 17 сентября 2017.
- . Роскомнадзор (24 октября 2014).
- ↑
archive.md
Адреса данного Архива Интернета:
На главной странице говорящие за себя поля:
- Архивировать страницу, которая сейчас онлайн
- Искать сохранённые страницы
Для поиска по сохранённым страницам можно как указывать конкретный URL, так и домены, например:
- microsoft.com покажет снимки с хоста microsoft.com
- *.microsoft.com покажет снимки с хоста microsoft.com и всех его субдоменов (например, www.microsoft.com)
- покажет архив данного url (поиск чувствителен к регистру)
- поиск архивных url начинающихся с http://twitter.com/burg
Данный сервис сохраняет следующие части страницы:
- Текстовое содержимое веб страницы
- Изображения
- Содержимое фреймов
- Контент и изображения загруженные или сгенерированные с помощью Javascript на сайтах Web 2.0
- Скриншоты размером 1024×768 пикселей.
Не сохраняются следующие части веб-страниц:
- Flash и загружаемый им контент
- Видео и звуки
- RSS и другие XML-страницы сохраняются ненадёжно. Большинство из них не сохраняются, или сохраняются как пустые страницы.
Архивируемая страница и все изображения должны быть менее 50 Мегабайт.
Для каждой архивированной страницы создаётся ссылка вида http://archive.is/XXXXX, где XXXXX это уникальный идентификатор страницы. Также к любой сохранённой странице можно получить доступ следующим образом:
- http://archive.is/2013/http://www.google.de/ — самый новый снимок в 2013 году.
- http://archive.is/201301/http://www.google.de/ — самый новый снимок в январе 2013.
- http://archive.is/20130101/http://www.google.de/ — самый новый снимок в течение дня 1 января 2013.
Дату можно продолжить далее, указав часы, минуты и секунды:
- http://archive.is/2013010103/http://www.google.de/
- http://archive.is/201301010313/http://www.google.de/
- http://archive.is/20130101031355/http://www.google.de/
Для улучшения читаемости, год, месяц, день, часы, минуты и секунды могут быть разделены точками, тире или двоеточиями:
- http://archive.is/2013-04-17/http://blog.bo.lt/
- http://archive.is/2013.04.17-12:08:20/http://blog.bo.lt/
Также возможно обратиться ко всем снимкам указанного URL:
http://archive.is/http://www.google.de/
Все сохранённые страницы домена:
http://archive.is/www.google.de
Все сохранённые страницы всех субдоменов
http://archive.is/*.google.de
Чтобы обратиться к самой последней версии страницы в архиве или к самой старой, поддерживаются адреса вида:
- http://archive.is/newest/http://reddit.com/
- http://archive.is/oldest/http://reddit.com/
Чтобы обратиться к определённой части длинной страницы имеется две опции:
В доменах поддерживаются национальные символы:
- http://archive.is/www.maroñas.com.uy
- http://archive.is/*.测试
Обратите внимание, что при создании архивной копии страницы архивируемому сайту отправляется IP адрес человека, создающего снимок страницы. Это делается через заголовок X-Forwarded-For для правильного определения вашего региона и показа соответствующего содержимого.
1997
After this tour through the 20th century, the Time Machine was set to 1997. Mark Graham, Director of the Wayback Machine and Vinay Goel, Senior Data Engineer, stepped on stage. Back in 1997, when the Wayback Machine began archiving websites on the still new World Wide Web, the entire thing amounted to 2.2 terabytes of data. Now the Wayback Machine contains 20 petabytes. Graham explained how the Wayback Machine is preserving tweets, government websites, and other materials that could otherwise vanish. One example: this report from The Rachel Maddow Show, which aired on December 16, 2016, about Michael Flynn, then slated to become National Security Advisor. Flynn deleted a tweet he had made linking to a falsified story about Hillary Clinton, but the Internet Archive saved it through the Wayback Machine.
Goel took the microphone to announce new improvements to Wayback Machine Search 2.0. Now it’s possible to search for keywords, such as “climate change,” and find not just web pages from a particular time period mentioning these words, but also different format types — such as images, pdfs, or yes, even an old Internet Archive favorite, animated gifs from the now-defunct GeoCities–including snow globes!
Thanks to all who came out to celebrate with the Internet Archive staff and volunteers, or watched online. Please join our efforts to provide Universal Access to All Knowledge, whatever century it is from.
Editor’s Note, 10/16/17: Watch the full event https://archive.org/details/youtube-j1eYfT1r0Tc
1912
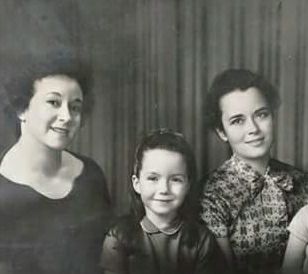
D’Anna Alexander (center) with her mother (right) and grandmother (left).
“Close your eyes and listen,” Rossi asked the audience. And then, out of the speakers floated the scratchy sounds of Billy Murray singing “Low Bridge, Everybody Down” written by Thomas S. Allen. From 1898 to the 1950s, some three million recordings of about three minutes each were made on 78rpm discs. But these discs are now brittle, the music stored on them precious. The Internet Archive is working with partners on the Great 78 Project to store these recordings digitally, so that we and future generations can enjoy them and reflect on our music history. New collections include the Tina Argumedo and Lucrecia Hug 78rpm Collection of dance music collected in Argentina in the mid-1930s.