9 способов найти удаленный сайт или страницу
Содержание:
- Как сделать бэкап сайта и спать спокойно?
- Онлайн сервисы для копирования простых сайтов
- Юридические проблемы с архивным контентом
- mydrop.io
- Статьи
- JS Examples
- Скопировать из браузера
- Вконтакте
- Как посмотреть историю на компьютере
- Какие есть ограничения у копий
- Регистрация на хостинге и залив сайта
- Как выглядит сайт-история?
- Элементы сайта-истории
- Залог успеха — эмоциональная вовлеченность
- Просмотр кэша страницы вручную
- Sorting an Array
- WWW: Сервис oldweb.today позволяет заглянуть в прошлое интернета
- Как удалить сайт из кэша
- Как найти архивные копии сайтов интернета Копилка эффективных советов
Как сделать бэкап сайта и спать спокойно?
Давайте поговорим откровенно, как говориться пока петух не клюнет, никто не хочет ничего делать и заботится о той или иной проблеме. Таже ситуация относится и к безопасности сайта. Многие владельцы работают в сети, делают свою работу, пишут блоги и даже могут не знать, что на их сайт попал вирус или же с зараженного компьютера или со скаченного на сомнительном сайте стороннего расширения в котором имелась брешь в безопасности.
Если Вы получите вирус на свой сайт то готовьтесь к тому что поисковые системы его обнаружат и пометят в поиске да и просто при его открытии как “Данные сайт может угрожать вашему компьютеру” и закроет доступ пользователя к нему а отсюда следует, что Вы будите терять аудиторию и доверие поисковиков которое Вы так долго заслуживали.
Когда произойдет беда а она может случиться в любой момент, скажу Вам у меня лично был вирус на одном из первых сайтов когда я только этому учился и после того как специалист начал анализ сайта оказалось что вирус сидел долгое время и это как замедленная бомба. Получилось так что она активировалась через несколько недель, а бэкапы сайтов хранятся не так долг как хотелось бы и поверх чистых резервных копий запишутся и зараженные а тут уже деваться некуда будет кроме как чистить сайт и проверять все файлы. Поэтому кроме создании бэкапа сайта на самом хостинге я советую делать резервную копию еще и себе на компьютер и просто отправлять в облачное хранилище, такое как приложение Яндекс.Диск или Гугл-диск, лично я делаю так, береженого бог бережет как говорится.
Давайте рассмотрим процесс создания резервной копии файлов своего сайта на Вашем хостинге, я это буду показывать на примере одного из сайтов. Для этого нам нужно создать соединение с хостером где хранится сайт либо через панель управления или же воспользоваться FTP соединением.
Онлайн сервисы для копирования простых сайтов
В сети существуют сервисы, которые копируют лендинг, чистят и изменяют его. Нужно указать целевой сайт, а сервис его скачает, очистит скопированную страницу от лишнего кода и чужих ссылок. Клиент получит новый одностраничник в виде готового архива для загрузки на хостинг.
Примеры таких сервисов:
copysta.ru — вы указываете адрес «донора» и сервис полностью скачивает лендинг, очищает его от лишнего кода, меняются контакты, формы заявок перестраиваются на почту заказчика, устанавливается админка для управления лендингом на хостинге заказчика. Стоимость услуг: 1 500-3 000 рублей. В самый дорогой тариф входит редактирование контента, стилей, замена изображений с целью сделать новый лендинг уникальным;
7lend.club – этот сервис предлагает услуги от простого скачивания, до очистки кода, установки счетчиков и форм заказчика и уникализации контента. Стоимость от $8 до $50 за лендинг;
copyland.pro – предлагает сделать копию лендинга любой сложности с очисткой от старых контактов, ссылок, счетчиков веб статистики и перестройку реквизитов, форм и счетчиков для заказчика. Стоимость услуг от 500 рублей; xdan.ru/copysite/ позволяет сделать локальную копию сайта. При этом можно очистить HTML от счетчиков, заменить ссылки или домен в ссылках, заменять указанные слова, всего 11 настроек. Минимальная подписка — 75 рублей на 24 часа.
Это лишь примеры сервисов. Таких подобных можно найти сотни если поискать.
580 просмотров
Отказ от ответственности: Автор или издатель не публиковали эту статью для вредоносных целей. Вся размещенная информация была взята из открытых источников и представлена исключительно в ознакомительных целях а также не несет призыва к действию. Создано лишь в образовательных и развлекательных целях. Вся информация направлена на то, чтобы уберечь читателей от противозаконных действий. Все причиненные возможные убытки посетитель берет на себя. Автор проделывает все действия лишь на собственном оборудовании и в собственной сети. Не повторяйте ничего из прочитанного в реальной жизни. | Так же, если вы являетесь правообладателем размещенного на страницах портала материала, просьба написать нам через контактную форму жалобу на удаление определенной страницы, а также ознакомиться с инструкцией для правообладателей материалов. Спасибо за понимание.
Юридические проблемы с архивным контентом
Против Internet Archive было возбуждено несколько дел за его усилия по архивированию Wayback Machine.
Саентология
В конце 2002 года Интернет-архив удалил из Wayback Machine различные сайты, критикующие Саентологию . В сообщении об ошибке говорилось, что это было ответом на «запрос владельца сайта». Позже выяснилось, что юристы Церкви Саентологии требовали удаления и что владельцы сайта не хотели, чтобы их материалы были удалены.
Healthcare Advocates, Inc.
В 2003 году компания Harding Earley Follmer & Frailey защитила клиента от спора о товарных знаках с помощью Archive’s Wayback Machine. Адвокаты смогли продемонстрировать, что требования истца были недействительными, основываясь на содержании их веб-сайтов за несколько лет до этого. Затем истец, Healthcare Advocates, изменил свою жалобу, включив в нее Интернет-архив, обвинив организацию в нарушении авторских прав, а также в нарушениях Закона США » Об авторском праве в цифровую эпоху» и Закона о компьютерном мошенничестве и злоупотреблениях . Healthcare Advocates утверждали, что, поскольку они установили файл robots.txt на своем веб-сайте, даже если после подачи первоначального иска Архив должен был удалить все предыдущие копии веб-сайта истца с Wayback Machine, однако некоторые материалы продолжали оставаться быть общедоступным на Wayback. Иск был урегулирован во внесудебном порядке после того, как Wayback устранил проблему.
Сюзанна Шелл
Активист Suzanne Shell подал иск в декабре 2005 года, потребовав Internet Archive платить 100000 $ HER США для архивирования ее сайта profane-justice.org в период между 1999 и 2004 Internet Archive подал декларативное суждение иска в окружном суде Соединенных Штатов для северного округа Калифорнии на 20 января 2006 г., добиваясь судебного определения, что Интернет-архив не нарушает авторские права Shell . Shell отреагировала и подала встречный иск против Internet Archive за архивирование ее сайта, которое, как она утверждает, нарушает ее условия обслуживания . 13 февраля 2007 г. судья Окружного суда США округа Колорадо отклонил все встречные иски, за исключением нарушения контракта . Интернет-архив не стал отклонять иски Shell о нарушении авторских прав, связанные с ее копировальной деятельностью, которые также будут проданы.
25 апреля 2007 г. Internet Archive и Сюзанна Шелл совместно объявили об урегулировании своего иска. Интернет-архив сообщил, что «… не заинтересован во включении в Wayback Machine материалов лиц, которые не желают архивировать свой веб-контент. Мы признаем, что г-жа Шелл имеет действующие и подлежащие исполнению авторские права на свой веб-сайт, и мы сожалеем что включение ее веб-сайта в Wayback Machine привело к судебному разбирательству «. Shell заявила: «Я уважаю историческую ценность цели Internet Archive. Я никогда не намеревался мешать достижению этой цели или причинять ей какой-либо вред».
Даниил Давыдюк
В период с 2013 по 2016 году порнографический актера по имени Daniel Davydiuk пытался удалить заархивированные образа себя из архива Wayback Machine, сначала отправив несколько запросов DMCA в архив, а затем, обратившись к Федеральному суду Канады .
mydrop.io
(реф. ссылка)
Удобный сервис, кроме фнкционала восстановления контента сайта имеет фунционал поиска доменов по различным параметрам. Пользуюсь им больше года.
Из преимуществ:
- широкий набор фильтров для поиска домена
- возможность подписки на фильтр
- информативная таблица доменов с полезными seo метрикам( TF, CF, DA, PA, LinkPad, SimilarWeb, LiveInternet, Alexa)
- показывают кол-во файлов, которые восстановить и размер в МБ
- показывают, есть ли ставки на домен через сервис expired.ru
- Есть своя Cms
- адекватные цены
- скидки при пополнении счета от 3000 руб.
- интерфейс на русском
Из минусов:
- нет пробного периода либо бесплатного восстановления, если восстонавливаемый сайт «небольшой»
- есть функционал предварительного просмотра, но он очень сыроват и на счета должна быть сумма не меньше чем стоимость восстановления
Статьи
JS Examples
Скопировать из браузера
Можно перенести данные из обозревателя в любой текстовый редактор. Для этого лучше всего подойдёт Microsoft Word. В нём корректно отображаются изображения и форматирование. Хотя из-за специфики документа может не очень эстетично выглядеть реклама, меню и некоторые фреймы.
Вот как скопировать страницу сайта:
- Откройте нужный URL.
- Нажмите Ctrl+A. Или кликните правой кнопкой мыши по любой свободной от картинок и flash-анимации области и в контекстном меню выберите «Выделить». Это надо сделать для охвата всей информации, а не какого-то произвольного куска статьи.
- Ctrl+C. Или в том же контекстном меню найдите опцию «Копировать».
- Откройте Word.
- Поставьте курсор в документ и нажмите клавиши Ctrl+V.
- После этого надо сохранить файл.
Иногда получается так, что переносится только текст. Если вам нужен остальной контент, можно взять и его. Вот как скопировать страницу веб-ресурса полностью — со всеми гиперссылками, рисунками:
- Проделайте предыдущие шаги до пункта 4.
- Кликните в документе правой кнопкой мыши.
- В разделе «Параметры вставки» отыщите кнопку «Сохранить исходное форматирование». Наведите на неё — во всплывающей подсказке появится название. Если у вас компьютер с Office 2007, возможность выбрать этот параметр появляется только после вставки — рядом с добавленным фрагментом отобразится соответствующая пиктограмма.
Способ №1: копипаст
В некоторых случаях нельзя скопировать графику и форматирование. Только текст. Даже без разделения на абзацы. Но можно сделать скриншот или использовать специальное программное обеспечение для переноса содержимого страницы на компьютер.
Сайты с защитой от копирования
Иногда на ресурсе стоит так называемая «Защита от копирования». Она заключается в том, что текст на них нельзя выделить или перенести в другое место. Но это ограничение можно обойти. Вот как это сделать:
- Щёлкните правой кнопкой мыши в любом свободном месте страницы.
- Выберите «Исходный код» или «Просмотр кода».
- Откроется окно, в котором вся информация находится в html-тегах.
- Чтобы найти нужный кусок текста, нажмите Ctrl+F и в появившемся поле введите часть слова или предложения. Будет показан искомый отрывок, который можно выделять и копировать.
Если вы хотите сохранить на компьютер какой-то сайт целиком, не надо полностью удалять теги, чтобы осталась только полезная информация. Можете воспользоваться любым html-редактором. Подойдёт, например, FrontPage. Разбираться в веб-дизайне не требуется.
- Выделите весь html-код.
- Откройте редактор веб-страниц.
- Скопируйте туда этот код.
- Перейдите в режим просмотра, чтобы увидеть, как будет выглядеть копия.
- Перейдите в Файл — Сохранить как. Выберите тип файла (лучше оставить по умолчанию HTML), укажите путь к папке, где он будет находиться, и подтвердите действие. Он сохранится на электронную вычислительную машину.
Защита от копирования может быть привязана к какому-то js-скрипту. Чтобы отключить её, надо в браузере запретить выполнение JavaScript. Это можно сделать в настройках веб-обозревателя. Но из-за этого иногда сбиваются параметры всей страницы. Она будет отображаться неправильно или выдавать ошибку. Ведь там работает много различных скриптов, а не один, блокирующий выделение.
Если на сервисе есть подобная защита, лучше разобраться, как скопировать страницу ресурса глобальной сети другим способом. Например, можно создать скриншот.
Вконтакте
Чего только не скрывалось под популярным ныне доменом vk.com. Кстати, использовать его стали не сразу, изначально в контакт можно было зайти только по URL: vkontakte.ru, но потом ситуация изменилась и администрация решила облегчить нашу с вами жизнь.
Кстати, само название социальной сети стало производным от фразы, которую Павел Дуров, создатель, постоянно слышал по радио «Эхо Москвы». Она звучала как «В полном контакте с информацией».
Изначально проект был создан как закрытый справочник студентов и выпускников. Об этом свидетельствует надпись на главной странице того периода.
Мог ли тогда представить Павел Дуров, насколько популярным станет его проект? Сейчас даже смешно смотреть на горделивую надпись: «Нас уже 350 000». Сейчас численность проекта насчитывает миллионы.
Интересных историй о этой социальной сети предостаточно, но на мой взгляд самая впечатляющая заключается в том, что вплоть до 2014 года через Одноклассники нельзя было послать ссылку на информацию, находящуюся Вконтакте. Система не блокировала их, а просто заменяла буквы в словах.
Еще один интересный факт, о котором многие пользователи помнят. В какой-то момент администрация сайта решила поменять дизайн личных страниц. Это вызвало бурю эмоций среди пользователей.
И тут и там кипели возгласы: «Верните стену, нет микроблогу». Павел Дуров был не преклонен. В моей памяти эти воспоминания все еще свежи, а тем не менее с той поры прошло 6 лет. Военные действия разворачивались в 2010 году. Согласитесь, сейчас смотришь на этот кошмар и думаешь, что там могло нравиться, за что воевали?
Интересный момент, но благодаря социальным сетям люди не только общаются между собой и зарабатывают, но и достигают других интересных целей. Хоть в свое время дизайн стены не вернули, зато деятельность пользователей на Facebook и Вконтакте вернула в мультсериал «Гриффины» умершего пса Брайна.
Ну и на последок мне бы хотелось порекомендовать вам курс «Из зомби в интернет-предпринимателя». Становитесь популярными и вы, достигайте своих целей.
Если вы переживаете, что ничего не умеете и не знаете, просто посмотрите как изначально выглядел любой сайт, тот же Яндекс. Время решает многое. Мы растем, двигаемся вперед и учимся на своих ошибках.
Подписывайтесь на рассылку и я помогу вам справиться со сложностями. До новых встреч.
Как посмотреть историю на компьютере
Если не получается найти недавно открытый файл, то история просмотров на этом компьютере и открытых приложений выполняется посещением журнала последних открытых программ, просмотреть недавние события в windows и поверить корзину.
История открытых файлов
Перечень недавно открытых или измененных файлов и история загрузок просматривается так:
- Win+R.
- В текстовом поле открывшегося окна напечатайте «Recent».
Просмотр корзины
В корзине так же можно при необходимости найти просмотренные файлы, которые были случайно удалены. Она открывается путем запуска программы посредством ярлыка на рабочем столе или через проводник, предварительно разрешив в настойках отображение скрытых папок. Она будет называться $Recycle.Bin.
Можно ли использовать специальное по для просмотра действий на пк
Любые действия в системе возможно отслеживать, используя особое по, например:
- Snitch;
- NeoSpy;
- SpyGo;
- Real Spy Monitor;
- Actual Spy и другие.
Какие есть ограничения у копий
Хочу внести ясность, что скопированный проект, даже если он точь-в-точь будет выглядеть как оригинал, это не означает что будут работать все функции. Не будет работать функционал, который исполняется на сервере, т.е. различные калькуляторы, опросы, подбор по параметрам — работать не будут 99%. Если функционал реализован с помощью Javascript, то будет работать.
Но .php скрипты скачать с сервера НЕВОЗМОЖНО, вообще НИКАК. Также не будут работать формы обратной связи и подачи заявок без ручных доработок. Учтите, что некоторые сайты имеют защиту от скачивания, и в таком случае вы получите пустую страницу или сообщение об ошибке.
Регистрация на хостинге и залив сайта
То, с каким хостингом работать — личное дело каждого, но все дальнейшие разъяснения буду вести на примере https://beget.com/ . В целом, особых отличий нет, так что можешь выбрать любой другой более-менее адекватный.
Проходим простую регистрацию, заполняем все поля которые хостер просит и вводим свой номер телефона, на него придет СМС с кодом подтверждения регистрации.
После этого, введешь код из сообщения, тебя перекинет на страницу, где указаны данные для авторизации. Письмо с ними же придет на почту.
Нажимаем кнопку «Начать работу» и попадаем в панель управления нашим хостингом.
Следующим шагом будет регистрация домена. Придумываем название доменного имени, вводим все свои паспортные данные и регистрируем на том же хостинге. Еще как альтернативу можно использовать другой хостинг для домена или напрямую у регистраторов.
Как выглядит сайт-история?
Помимо того, что здесь присутствует определенный сюжет, на сайтах-историях многое строится на взаимодействии визуальных частей и интерактивности. Применение техник сторителлинга на сайтах может быть весьма разнообразным. Порой они могут переплетаться с инфографикой, видео и т. п. Иногда сайты полностью основаны на сторителлинге, иногда – лишь частично.
Посмотрите на два сайта, при создании которых применялась техника визуального сторителлинга.

Нажмите для перехода

Нажмите для перехода
На самом деле сайты-истории очень разнообразны. Они могут рассказывать о том, как использовать тот или иной продукт компании, рассказывать о технологиях, которые применяются в производстве, или даже просто создавать определенное настроение у посетителя. Все зависит от целей компании.
Элементы сайта-истории
Любая история – это в первую очередь повествование. История на сайте – не исключение.
Повествование складывается из следующих элементов:
- Персонаж. Выступать в качестве персонажа может продукт компании, сам бренд или что-то еще. Может быть и вымышленный персонаж, который несет в себе собирательный образ, например, целевой аудитории компании.
- Конфликт (событие). В роли конфликта могут быть какие-либо волнующие целевую аудиторию проблемы. Ситуации, в которые попадает клиент и в решении которых может помочь компания.
- Действие. Это те действия, который должен совершить клиент, чтобы решить конфликт, проблему. И в истории рассказывается, какие это должны быть действия. Тут могут быть и действия, которые совершает компания, чтобы решить проблему клиента. Часто описывается конечный результат действий, положительные эмоции от использования продукта, счастье клиента после того, как проблема решена.
Это три основополагающих элемента хорошей истории. Как именно облечь их в визуальную форму на сайте — зависит от задачи
Главное здесь – это не упустить основную идею, отказаться от лишних отвлекающих внимание элементов, чтобы провести внимание зрителя от начала истории (сайта) до конца
Залог успеха — эмоциональная вовлеченность
Залогом успеха сайтов-историй является то, что они вызывают высокую эмоциональную вовлеченность. Они интересные, запоминаются, результативно транслируют нужные идеи.
По данным Koozai, сегодня люди сканируют контент, а не вникают в него
Ищут то, что их заинтересует, и останавливают на этом внимание. Если же контент не сможет выделиться из массы других сообщений и вызвать интерес, то можно считать, что он создан зря – то есть никогда не сможет выполнить возложенные на него функции
Техники сторителлинга позволяют создать сильный визуальный контент. Это понимает большинство маркетологов: по исследованиям Social Media Examiner, процент использования такого контента продолжает расти
Большое внимание уделяется видео. Видеоистории и их применение – в том числе и на сайтах – имеют решающее значение в эффективности маркетинговых кампаний
Исследования направлений движения глаз человека по веб-странице показывают, что пользователи сайтов обращают пристальное внимание на информативно насыщенные изображения. И, соответственно, проводят дольше времени на сайте, где эти изображения есть
И снова здесь выигрывают сайты, созданные с применением сторителлинга.
Есть и другие аспекты, которые влияют на результативность подобных сайтов.
Во-первых, они выделяются среди других, позволяют захватить внимание. Сегодня время, когда информации слишком много и из-за перенасыщенности различными рекламными сообщениями, брендам все труднее завладеть вниманием потенциальных клиентов
Использование историй помогает решить эту проблему. Ведь сама структура историй создаётся так, чтобы захватывать внимание зрителя и вести его от начала истории до конца.
Во-вторых, сообщение поданное с помощью сторителлинга легче для восприятия, это обусловлено тем, как наш мозг воспринимает информацию. А всем известный факт, если перегрузить внимание или сделать сообщение сложным, то оно перестанет работать. Чем проще, тем лучше.
Все это в комплексе и делает сайты-истории результативным инструментом достижения маркетинговых целей.
Просмотр кэша страницы вручную
В Google
На странице с выдачей (SERP) следует навести мышку на конкретный результат выдачи и кликнуть «Сохраненная копия»:
Просмотр кэшированного документа в Google
Естественно, запрос можно сформировать как угодно. На картинке приведён пример просмотра кэша конкретной страницы — http://web-ru.net/category/internet/.
404 в Google
У каждой из этих 4-х поисковых систем сверху можно обнаружить надпись вроде такой «по состоянию на 9 окт 2012 15:13:22 GMT». Т.е. отображается веб-страница такой, какой она была 9 октября 2012 года.
Кэш в Яндексе
Смысл тот же: вводим запрос, наводим курсор на один из результатов выдачи и кликаем на «Копия»:
Посмотрим кэш страницы в Яндекс
Нужно кликнуть на маленькую стрелочку, расположенную около URL-адреса страницы:
Кэш документав Bing.com
В Mail.ru
В этой поисковой системе лучше смотреть кэш отдельных страниц, а не, например, категорий. Просто потому что в Мэйле при запросе, содержащем URL категории, могут быть выведены ссылки на несколько статей этой категории, а не на саму категорию. Хотя Mail.ru как поисковик пока особо не интересен, и можно об этом вообще не думать. Ну а в целом, всё то же:
Кэш документа сайта в Mail.ru
Кстати, если в Гугле, Яндексе и Bing ввести «человеческий» запрос и посмотреть кэшированный документ, то этот запрос будет выделен на открытом сайте жёлтым цветом. Примерно так:
Выделенный запрос в кэше страницы в Гугле
Это может быть способом посмотреть, например, как оптимизированы тексты на сайтах ваших конкурентов
Таким образом, зная дату и время занесения страницы в кэш Google, Yandex и т.д. можно понять, известно ли поисковой системе о произошедших на ней изменениях или пока ещё нет.
Случайные публикации:
- Как не проиграть в SEO войне. Обзор SEO программы Netpeak spiderSEO войны это не миф, а абсолютная реальность. Каждый день, каждый час…
- Конкурс депозитов от Binpartner.com 2017…ртнерской программе от компании BinPartner будет проводиться
- Поведенческие факторы поисковых систем. Как улучшить ПФ и в чём суть?После проведённого онлайн-семинара по продвижению сайта в поиск…
- Как отключить/включить куки в браузерах Firefox, Explorer, Opera, Chrome. Должны ли быть куки отключены?Это дополнение к статье о просмотре и удалении cookies в разных…
- Как заработать на TeaserNet?Без тизерных сетей, уже невозможно представить жизнь интернета. Эти рекламные объявле…
Оставьте комментарий:
Sorting an Array
WWW: Сервис oldweb.today позволяет заглянуть в прошлое интернета
Если ты застал ранние деньки интернета, то наверняка любишь поностальгировать: вспомнить диалап и домашние страницы с гифками, первую версию «Яндекса» с окурком, старый добрый Netscape Navigator и прочие радости почти двадцатилетней давности. Если же ты добрался до Сети только в двухтысячных, то тебе будет полезно узнать, с чего всё начиналось.
Удовлетворить любопытство или потешить ностальгию можно при помощи Internet Archive: вбил адрес, выбрал дату, дождался загрузки и перед тобой давняя-предавняя версия какого-нибудь сайта. Но всё же смотреть на старый интернет через современный браузер слегка неспортивно.
Сервис oldweb.today (это и название и очень удачный URL) предоставляет куда более полный экспириенс. Когда ты задашь URL и дату, в твоем браузере откроется окно с виртуальной машиной, в которой крутится старая операционная система и один из старых браузеров. На выбор NSCA Mosaic 2.2, Netscape Navigator 3 и 4 и Internet Explorer 4 и 5.
Данные сайтов будут подгружаться из всё того же Internet Archive, но для витуалки эти данные будут выглядеть как самый настоящий интернет. Каждая сессия может длиться не дольше десяти минут, но этого вполне достаточно, чтобы испытать мощное умиление или шок от того, как убого раньше выглядели сайты. А если время выйдет, то никто не мешает загрузить по новой.
В основе oldweb.today — технология Docker, с которой читатели Х должны быть отлично знакомы (если ты не знаком, см. номер 196 за май 2015). Внутри Docker поднимается эмулятор старой ОС, и уже в нем — браузер, окно которого и транслируется пользователю. Для особо любопытных есть исходники всей пирамиды.
Как удалить сайт из кэша
Чтобы ускорить индексирование страницы поисковиками, владельцы ресурсов удаляют из кэша старые версии. Так, Яндекс и Google не обходят стороной ссылки, которые уже прописаны у них системе. Обе системы проводят периодическую актуализация данных, но этим занимается робот. Из-за такой специфики обновление информации происходит дольше, чем при вмешательстве владельца сайта.

Чтобы удалить страницу из кэша Google, необходимо:
- Зайти в сервис Webmaster.
- Перейти в раздел меню “Удалить URL-адрес”.
- Нажать на кнопку “Временно скрыть”, чтобы страницы перестала отображаться в результатах поиска.
- Ввести адрес ссылки.
- Нажать кнопку “Продолжить”.
- Выбрать необходимый тип удаления, в данном случае — второй пункт.
- Подтвердить запрос.
- Дождаться, когда заявка перейдет из статуса “Ожидание” в “Выполнено”.
https://youtube.com/watch?v=3y43CPA6lUc
Заблокированный сайт — еще не приговор. Сервисы Яндекс и Гугл постоянно создают кэш всех ресурсов, поэтому пользователи смогут получить к ним доступ даже после удаления контента с серверов. Для этого не потребуется дополнительный софт. Открыть копию можно всего в 2 клика. При этом она будет соответствовать последней актуальной версии сайта. Страницы из кэша могут спасти веб-программистов, если изменения кода обрушили весь интерфейс, а вспомнить, как он должен выглядеть, не получается.
Как найти архивные копии сайтов интернета Копилка эффективных советов
Как найти архивные копии сайтов интернета или машина времени для сайтов
Существует настоящая, реальная машина времени, в которой можно ненадолго вернуться в прошлое и увидеть, например, как выглядел тот или иной сайт несколько лет назад. Думаете, никому не нужны копии сайтов многолетней давности? Ошибаетесь! Для очень многих людей сервис по архивированию информации весьма полезен.

Во-первых, это просто интересно! Из чистого любопытства и от избытка свободного времени можно посмотреть, как выглядел любимый, популярный ресурс на заре его рождения.
Во-вторых, далеко не все владельцы сайтов ведут свои архивы
Знать место, где можно найти информацию, которая была на сайте в какой-то момент, а потом пропала, не просто полезно, а очень важно
В-третьих, само по себе сравнение является важнейшим методом анализа, который позволяет оценить ход и результаты нашей деятельности. Кстати, при проведении анализа веб-ресурса очень эффективно использовать ряд методов сравнения.
Поэтому наличие уникальнейшего архива веб-страниц интернета позволяет нам получить доступ к огромному количеству аудио-, видео- и текстовых материалов. По утверждению разработчиков, «интернет-архив» хранит больше материалов, чем любая библиотека мира. Мы попали в правильное место!
Что нужно, чтобы найти копии сайтов интернета
Для того, чтобы отправиться в прошлое, нужно перейти на сайт archive.org и воспользоваться поисковой строкой.
Простой поиск в архиве сохраненных сайтов выдает нам ссылки на все сохраненные копии запрашиваемой страницы.
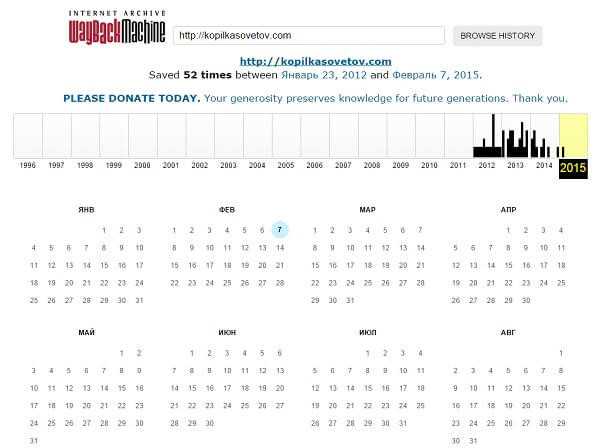
Из этого скриншота видно, что сайт kopilkasovetov.com был создан в 2012 году (Кстати, важно отметить, с помощью практически идеального хостинга Спринтхост — рекомендую!). Переключаясь на нужный нам год, можно увидеть даты, выделенные кружочками, это и есть даты сохранения копии сайта
Например, в 2015 году, пока можно будет увидеть только одну копию от 7 февраля.
Конечно, это потрясающий ресурс! Ведь здесь индексируются и архивируются все сайты интернета! Это не только скриншоты… Имея в руках такой инструмент, можно восстановить массу потерянной со временем информации.
Надо заметить, что, безусловно все восстановить однозначно не получится, так как если на страницах сайта используются элементы Java Script, или скрипты или графика взяты со стороннего сервера, то на восстановление такой информации рассчитывать не придется
Поэтому к сохранению данных своего сайта нужно относиться с особенным вниманием, несмотря ни на что
Пользуясь случаем, я сделала скриншоты и восстановила в памяти, как выглядел мой сайт, начиная с 2012 года. Любопытно посмотреть))
Сайт буквально недавно «родился»)) Январь 2012…

Проходит время, и хочется что-то изменить… Конец 2012-го.
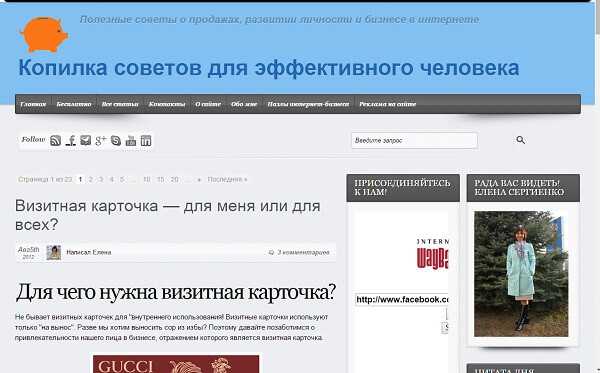
Наверное, пора уже что-то менять. 2013-й. Это тема, которая и сегодня установлена на моем сайте.
К смене темы отношусь с осторожностью, так как помню последний «переезд», после которого несколько месяцев восстанавливала посещаемость сайта. Как-то не очень удачно получилось
Надеюсь, что и моим читателям эта замечательная интернет-библиотека — «машина времени» сможет помочь перемещаться во времени, когда они этого захотят. Посмотрите, как выглядели раньше некоторые сайты, еще во времена своего зарождения. Какими раньше были google или яндекс, можно увидеть только на archive.org, аналогов у этого ресурса нет. Приятного путешествия, друзья!