Парсеры вордстата
Содержание:
- 8 лайфхаков для ресторанного SMM
- Key Collector и СловоЕБ
- Версии навигатора и системные требования для Андроид
- Дополнительные возможности
- Базовые операторы Яндекс.Вордстат
- Приложения
- Инструменты для упрощения работы с «Вордстатом» – расширения и программы
- Функция фильтрации в интерфейсе Топвизора
- Что можно делать с помощью SQL запросов
- Стереотипы в отношении НЧ запросов.
- Как автоматизировать подбор ключевых слов в Вордстате
- Rush Analytics
- Кому и зачем следует знать принцип работы Яндекс.Вордстат?
- Пошаговая инструкция по работе с Yandex Wordstat
- Букварикс
- Яндекс Wordstat
8 лайфхаков для ресторанного SMM
Key Collector и СловоЕБ
Это комплексная десктопная программа, в которой есть буквально всё для работы с контекстной рекламой, в том числе сбор семантического ядра.
Чтобы сделать парсинг в Key Collector, добавляем фразы:
Запускаем парсинг. Рекомендация: выбирайте глубину 2. Так вы сразу получаете не только результаты парсинга, но и дополнительную выдачу по каждому из них.
Подробнее настройки описаны здесь.
Также Key Collector позволяет очистить семантическое ядро от «мусора», а именно:
- Ключевиков, которые содержат ненужные слова;
- Повторов слов;
- Стоп-слов (информационные запросы, города, в которых не действует предложение, «бесплатно», «дешево», субъективные определения и т.д.);
- Запросов с нулевой частотностью.
Есть бесплатный аналог Key Collector – СловоЕБ. Основное его ограничение – в источниках. Он работает только с левой и правой колонкой в Wordstat, Rambler.Adstat и поисковыми подсказками Яндекс и Google.
Для сравнения: Key Collector поддерживает всё вышеперечисленное, плюс Google Ads, подсказки Mail, Wordstat полностью и системы аналитики, установленные на сайте (Google Analytics, Яндекс.Метрика, LiveInternet).
Другие ограничения программы СловоЕБ:
- Проверяет частоту запросов только по Wordstat, а КК также по Yandex.Direct, Google.Ads, LiveInternet, Rambler.Adstat, APIShop.com;
- Оценивает конкурентность запросов для Яндекс и Google, в то время как в КК 4 формулы оценки KEI, которые можно менять вручную.
Однако этого функционала будет вполне достаточно, если у вас небольшой проект.
Версии навигатора и системные требования для Андроид
Дополнительные возможности
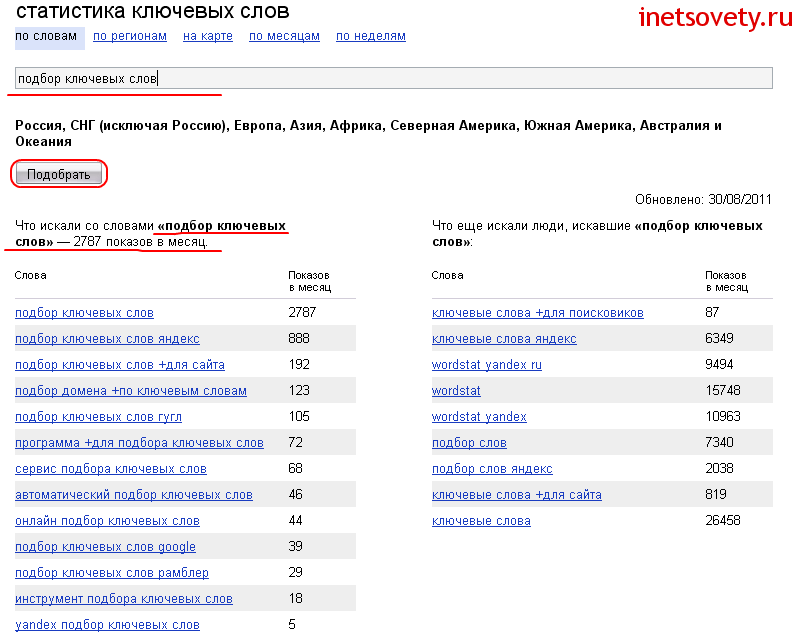
На иллюстрации выше, цифрами отмечены: 1 — сам запрос, 2 — дата обновления статистики Яндекса по данным фразам, 3 — суммарное число показов по фразам которые соответствуют запросу, 4 — общее число показов по фразе.
Здесь очень важно не путать общее число показов из колонки 4 и число точных запросов по фразе, которое можно получить с использованием операторов «Кавычки», «Восклицательный знак» и «Квадратные скобки». К дополнительным возможностям WordStat отнесем изучение истории (сезонности) спроса в тематике, получение частоты в заданном регионе и анализ популярности фраз в мобильном поиске (планшеты, мобильные телефоны)
К дополнительным возможностям WordStat отнесем изучение истории (сезонности) спроса в тематике, получение частоты в заданном регионе и анализ популярности фраз в мобильном поиске (планшеты, мобильные телефоны).
Данные функции часто оказываются полезны при планировании рекламных кампаний.
История запроса
Можно быстро понять, как меняется интерес к выходу новой модели «IPhone 6S». К сожалению, в текущий момент история запросов не поддерживает операторы («ИЛИ», «Группировка», «Квадратные скобки»).
Изучение динамики по запросу . Хорошо видны резкие сезонные всплески и провалы после наступления января.
Частота в заданном регионе
Отдельного упоминания заслуживает получение частоты запроса в заданном регионе. С помощью разделения общей частоты запроса по регионам можно оценить как частоту заданного запроса в интересующей нас регионе (Москва, Москва и область, Санкт-Петербург и т.д.), так и относительную популярность того или иного запроса в регионе.
Из примера приведенного ниже видно, что запросы со словами «купить» и «Казань» преимущественно задают жители г. Казань, что весьма очевидно. Использование данной функции на практике иногда открывает и более неожиданные закономерности.
Сбор (парсинг) запросов заданной длинны
На практике бывает полезным использовать приём парсинга запросов заданной длинны (из 2, 3, 4 слов и так далее) с вхождением ключевого слова. Данная возможность оказывается особенно актуальной, если вы работаете в популярной тематике и сбор первых 41 страниц не позволяет получить все поисковые фразы.
Для сбора всех фраз с длиной в 3 слова используется конструкция вида:
«IPhone IPhone IPhone»
Данный запрос позволяет собрать уже не просто 41 страницу поисковых фраз произвольной длины, а 41 страницу фраз из трёх слов с вхождением «IPhone». Последовательный анализ запросов с длиной от 2 до 7 слов позволяет существенно увеличить охват целевой аудитории.
Для ускорения сбора частот, быстрого парсинга Яндекс.Вордстат и хранения целевых ядер, рекомендуется использовать программы и онлайн-сервисы автоматизации, к числу которых можно отнести «Пиксель Тулс». После быстрой настройки параметров сбора, можно получить широкое семантического ядро в рамках тематики.
Анализ проведён с помощью инструментов в сервисе Пиксель Тулс.
Детальный анализ словоформ для ВЧ-запросов
Для ВЧ-запросов длиной в 2 и более слов может пригодиться анализ частоты встречаемости словоформ. Для этого требуется ввести исходную фразу, скажем, «продвижение сайтов» и далее последовательно исключать точные популярные написания с помощью комбинации операторов вида — -«», что приводит к исключению наиболее частотной формы написания из статистики и появлению второй по популярности версии. Далее процедуру можно повторить.
Базовые операторы Яндекс.Вордстат
Для работы со статистикой ключевых слов в Вордстат применяются дополнительные операторы, помогающие конкретизировать облако запросов.
Восклицательный знак
!Восклицательный знак помогает быстро подобрать запросы с интересующей словоформой одного слова или всех слов из ключевого запроса.
Кавычки
«Кавычки» предполагают, что сервис выдаст только количество показов фразы, заключенной в них. Также он может выдать варианты с разными окончаниями и количество показов с переставленными словами.
Квадратные скобки
Позволяют выдавать статистику ключевых слов в Вордстат без их перестановки местами. Т.е. квадратные скобки фиксируют порядок слов в запросе. Оператор полезен для оценки популярности похожих высокочастотных фраз.
Совместное применение операторов Вордстата
Вводя запросы в Яндекс. Вордстат, можно комбинировать операторы, чтобы уточнять результат:
· (Одноклассники | ОК | ок ) (реклама | +как | +какие | фишки | правила).
· !японские !суши -нори
· «».
Использование инструмента Вордстат — несложная, но кропотливая работа, благодаря которой можно выяснить многое об интересах своей целевой аудитории.
Приложения
Лидер в этом сегменте – key-collector.ru . Это мощный десктопный инструмент для парсинга ключей из Вордстата. Не нужно вручную собирать, программа расширяет пул запросов исходя из вашего маленького списка. Вам нужно только определить основные ниши и указать приложению, что искать.
У программы есть пара недостатков:
- сложности в настройках. Вот ссылка на гайд в помощь – настройки Key Collector с нуля.
- приложение платное. Вот расценки:
Есть бесплатный аналог с более узким функционалом – «Словоёб» (уж простите, такое название, создатели были очень креативными).
Для ведения нескольких или крупных проектов, такие приложения просто незаменимы. Потратьте полчаса на настройку один раз и вы сэкономите десятки часов при постоянном использовании программ в продвижении проектов.
Еще обратите внимание на дополнительный источник ключей – это «Букварикс». Программа похожа на Wordstat, но информация по запросам разнится из-за разных алгоритмов сбора
Если вы хотите научиться использовать эти приложения, собирать правильную семантику и продвигать сложные проекты тогда вам сюда:
А если планируете настраивать контекстную рекламу, то вам подойдёт вот эта подборка курсов:
Инструменты для упрощения работы с «Вордстатом» – расширения и программы
Работать с «Вордстатом» просто – научиться сносно пользоваться пятью операторами можно за полчаса. А вот собирать большие объемы данных и работать с ними – уже сложнее. В первой части статьи были рассмотрены основы работы с «Вордстатом», потому что без понимания какие данные и почему отдаются сервисом, невозможно эффективно использовать средства автоматизации. Вот три самых популярных программы:
- «Яндекс Вордстат Ассистент»;
- «Яндекс Вордстат Хелпер»;
- «Кей Коллектор» (и его бесплатная версия).
«Яндекс Вордстат Ассистент»
На официальном сайте https://semantica.in/tools/yandex-wordstat-assistant выбираем браузер, который используется для работы. После установки возле каждого запроса появится возможность добавить или удалить его из списка:
Все «проплюсованные» запросы добавляются в список. После того, как все нужные запросы скопированы в список, можно:
- Посмотреть в списке количество добавленных фраз и их суммарную частотность (цифры 2 и 25 над списком на скриншоте выше).
- Скопировать фразы в буфер обмена.
- Скопировать фразы и их частотность в буфер обмена.
- Отсортировать запросы по убыванию или по возрастанию в алфавитном порядке, по порядку добавления в список или по частотности.
Основной плюс – простота использования, дополнение бесплатное. Основной минус – инструмент собирает только фразу и базовую частотность запроса.
«Яндекс Вордстат Хелпер»
Установить дополнение можно также выбрав браузер на странице официального сайта https://arcticlab.ru/yandex-wordstat-helper/
Фактически, это полный аналог предыдущего дополнения, но чуть более удобный (сортировку можно сделать в 1 клик).
Еще один недостаток обоих дополнений – муторная ручная работа при работе с большим количеством запросов. Я уже писал ранее, что популярный запрос может отдавать данные на 40 страницах по убыванию частотности. Чтобы только собрать эти данные, нужно будет произвести более 80 кликов (40 переходов на следующую страницу и 40 добавлений запросов в дополнение).
«Кей Коллектор», описание и настройка парсера данных из «Яндекс.Вордстат»
По сути, это комбайн для работы с данными. Я не буду пересказывать справку программы, а напишу только о плюсах и минусах «Кей Коллектора» при работе с «Вордстатом».
Сначала о минусах. Их всего четыре:
- Как я уже писал, программа платная.
- Потребуется завести отдельные аккаунты в «Яндексе» для «Кей Коллектора», так как при частых автоматических запросах может быть затруднен доступ к «Вордстату» (будет выбиваться несколько капч на каждый запрос).
- Нужно будет 1 раз настроить программу по справке или по скриншотам моих настроек для быстрого сбора данных.
- Потребуется оплатить 1 из сервисов антикапчи, чтобы можно было поставить программу на сбор данных и забыть о ней. Хотя я собираю данные в промышленных объемах (сотни тысяч запросов в месяц), мне на 3 компьютера хватает 150–350 рублей в месяц на оплату антикапча-сервисов.
Теперь интерфейс:
Полный обзор возможностей программы лежит за рамками темы о «Вордстате», потому что краткий видео обзор возможностей программы занимает около полутора часов. Я обозначу только настройки, которые нужны для того, чтобы быстро начать работать с «Вордстатом».
Три волшебных кнопки:
- Сбор фраз из «Яндекс Вордстат». Аналогично тому, как если бы вы руками с каждой страницы копировали запрос и частотность в таблицу.
- Сбор поисковых подсказок. Если вы каждую фразу будете вставлять в поиск и выписывать для нее поисковые подсказки – получите такой же результат, как и программа.
- Сбор частотностей в кавычках «» и с уточнением словоформы «!». Работает так же, как если бы вы каждый запрос вбивали с этими операторами и записывали цифры.
Порядок действий – сначала собираем запросы (1), затем частотность (3). По интересующим запросам собираем подсказки (2) и снова частотность (3).
Полученный результат:
Фактически, сбор десятков тысяч запросов со всеми данными занимает 2-3 часа.
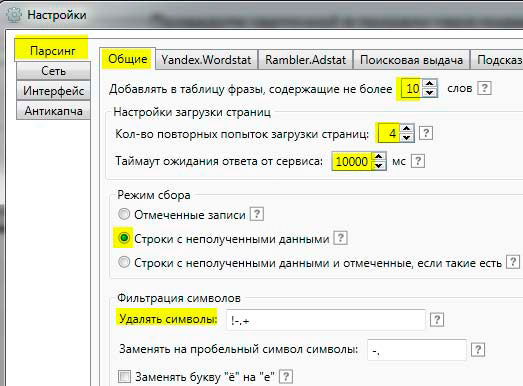
Я приведу настройки, которые нужно сделать, чтобы собирать данные с лучшим сочетанием скорости и дешевизны (не супер быстро, но с небольшим расходом на антикапчу). По порядку:
Сбор разных видов частотностей проходит через «Яндекс.Директ» – настраиваем и его:
Кроме этого в верхней части этого окна нужно добавить несколько аккаунтов «Яндекса»:
И последнее что нужно сделать – зарегистрироваться в любом из совместимых сервисов разгадки капчи, получить в нем код для работы и ввести его в настройках:
Я пробовал разные схемы настроек, эта – самая эффективная и простая.
Остальные 200 кнопок и настроек я предлагаю вам освоить самостоятельно (-:
Существует и бесплатная версия «Кей Коллектора» – программа «Словоеб», которая так же позволяет полноценно работать с «Вордстатом». Ссылка на сайт программы.
Функция фильтрации в интерфейсе Топвизора
Итак, мы создали с помощью системы несколько блоков необходимых нам словосочетаний для ядра. В ходе сбора семантики посредством операторов (включая минус-фразы) уже отсеялась большая часть «мусора», включая «пустышки».
Дальнейшие действия по фильтрации зависят от того, какого типа и тематики сайт вы имеете. Многие небольшие коммерческие ресурсы (уж только что созданные точно) продвигаются не только под низкочастотные, но и сверх-низкочастотные запросы, поэтому в этом случае, возможно, стоит сохранить все собранные на этот момент ключи.
А вот, например, для информационного проекта, даже свежеиспеченного, ключевики с очень маленькой частотностью (например, менее 10) порой просто нерентабельны. Никакого сколь-нибудь заметного трафика они не дадут, а драгоценное время отнимут. Поэтому жмем кнопку фильтрации и выбираем ее вид «по частоте» из выпадающего меню:
Обратите внимание, что при таких настройках запросы с установленной минимальной частотой не будут удалены (это можно сделать в любое время), а упадут в отдельную группу, предложенную Топвизором (кстати, ее название по умолчанию можно изменить). Возможно, впоследствии кое-какие из этих ключей могут пригодиться (например, возрастет частотность, что иногда случается)
Кстати, существует возможность выбрать поисковые запросы не только с частотой ниже какого-то значения, но и выше (знаки «больше» и «меньше» также выбираются из выпадающего меню). Вот какие еще какие возможности фильтрации по частоте предлагает система:
Чего тут только нет! Вы в силах отфильтровать все запросы во всех группах по частотности, сами группы по частоте, алфавиту, дате добавления, применить инструмент «Найти и заменить», даже сменить протокол ссылок на целевые страницы и т.п. В общем, есть все для комфортной работы.
Что можно делать с помощью SQL запросов
Стереотипы в отношении НЧ запросов.
Здесь есть ряд стереотипов, которые уже устоялись в результате прохождения каких-то курсов, например, в Бизнес молодости есть такое, чем больше запросов в рекламной кампании, тем больше заказов.
Вот мы и разберем некоторые из них.
Вот, например, классификация запросов относительно контекстной рекламы.

Понятно, есть запросы горячие – это купить, заказать. Они формируют желание клиента немедленное решить свою проблему, удовлетворить свою потребность. Под эти запросы рекламу и нужно делать, это самые эффективные запросы.
Есть также информационные запросы, когда человек ищет какую-то информацию. Допустим, хочет уточнить какие-то детали, допустим, он купил ноутбук и не знает, как там чего подключить и формирует информационный запрос.
Навигационный запрос – это уже поиск какого-го конкретного бренда или магазина.
Есть еще новый вид запроса – мультимедийный. Сейчас много видео в YouTube на разную тематику, и вот ищут там, к примеру – как положить плитку в ванной видео – это мультимедийный запрос.
Есть также запросы не определенные, по которым сложно сказать, что человек хочет – то ли он купить хочет, то ли уточнить детали. И здесь нет ясности.
Есть вопросы еще брендовые или привязанные к гео. Гео – это допустим – интернет магазин ноутбуков Москва, что то такое. Так же это такие запросы, которые могут содержать точное наименование продукта, как ноутбук Aser z50, то есть человека интересует какая-то модель.
И вот он первый стереотип, который появляется, когда собирают много низкочастотных запросов: чем больше запросов в компании, тем больше продаж.
Думаю, все слышали такое.
Вот и начинают люди собирать для своей рекламной компании миллионы слов, нужных и ненужных. Чтобы организовать такой подбор слов рисуют майнд карты, складывают перескладывают слова в Excel, опустошают базу Пастухова и делают прочие ужасы.
Это на самом деле это не правда.
Потому что самый продающий запрос – это горячий.
Но они очень редко бывают низкочастотными, как правило это высокочастотные или среднечастотные запросы. Они собой олицетворяют спрос в тематике, спрос в нише. Именно эти горячие запросы.
Что позволяют получить вообще большое количество запросов? – больше кликов, но количество кликов не равно количеству продаж.
То есть если вы нашпигуете рекламную кампанию большим количеством низкочастотных запросов, это не означает, что у вас будет большое количество заказов. Скорее всего, у вас будут клики, но заказов будет не очень много.
Второй момент – когда говорят, что НЧ запросы ведут к росту ctr кампании.
Это касается такого момента, как искусственно сформированной семантики, о чем рассказывают, некоторые инфо бизнесмены, которые занимаются обучением настройки Директа.
Что происходит.
Какая логика – они в Excel формируют, складывают слова, получаются запросы, которые никто не ищет, у них 0 показов, если смотреть по Яндекс Вордстату. Но логика в том, что, если у вас допустим таких запросов 300-400 в кампании, то когда-нибудь по ним пройдет все равно какой-то 1 показ, кто-то догадается, и будет показ. Всего возможно 300-400 показов по таким запросам за квартал и у вас может быть будет несколько продаж. Как бы логика объективна, такое действительно может быть.
Но есть такая тема, как общий ctr рекламной кампании, то есть если в кампании допустим тысяча слов, тысяча объявлений, то Директ подсчитывает ctr по каждому ключу. Но когда он суммирует ctr по всем ключам, то получается общий ctr по кампании.
Так вот, если в кампании висит много, допустим, 200-300 объявлений, по которым 0 показов, у них соответственно и ctr 0, что естественно ухудшает общий ctr. По этому поводу даже в справке Яндекса есть такое: отключать и убирать те фразы, по которым ctr равен нулю, то есть нет кликов по показов. Эту ухудшает общий ctr и приводит к тому, что общие расходы по Директ повышаются.
Потому что чем ниже ctr, тем выше расход, к тому же есть такое понятие, как карма домена, хоть Яндекс и отрицает, но тесты показывают, что карма домена существует. Она ухудшается, в результате растет цена за клик. И мы, получив, благодаря искусственной семантике допустим 5 заказов за несколько месяцев, мы заплатили больше денег за остальные наши клики и заказы, потому что у нас выросла общая цена за клик.
Как автоматизировать подбор ключевых слов в Вордстате
Даже с помощью плагинов вручную работать с Вордстатом достаточно трудоемко. Но процесс можно автоматизировать. Для этого нам пригодится два инструмента Click.ru:
- Подбор слов и медиапланирование.
- Парсер частотностей Вордстат.
Собираем ключевые слова
Зарегистрируйтесь / авторизуйтесь в Click.ru и откройте инструмент «Подбор слов и медиапланирование».
Укажите базовые данные:
- URL сайта, для которого будете собирать слова;
- место размещения рекламы (поиск, контекстно-медийная сеть или оба варианта).
- регионы, в которых планируете показывать рекламу.
По умолчанию система фиксирует стоп-слова (оператор +, который мы рассматривали выше) и проводит кросс-минусацию. Галочки лучше не снимать.
После указания всех необходимых данных нажмите «Начать новый подбор».
Система проанализирует сайт (URL которого указали на этапе базовых настроек). На основе контента сайта система автоматически подберет релевантные ключевые фразы.
Вы можете добавить к этому списку свои слова или воспользоваться дополнительными инструментами автоматического подбора:
- Слова конкурентов. Здесь нужно будет указать URL сайтов-конкурентов. Система проанализирует их и соберет семантику.
- Слова из счетчиков статистики. Откройте доступ к счетчикам Яндекс.Метрики и/или Google Аналитики. На основе их данных система подберет запросы, по которым к вам на сайт приходили посетители.
Автоматический подборщик слов — это хорошо. Но нам нужны данные Вордстата
Обратите внимание на блок «Ручной подбор слов». Это и есть подборщик на основе данных Вордстата
Как работает подборщик:
1. Введите по одному или списком базовые слова:
Система для каждого слова определяет частотность, а также прогнозы по кликам и бюджету в зависимости от желаемой доли трафика (указываете в столбце «Позиция»).
2. Для просмотра вложенных запросов нажмите на значок списка слева от заданной фразы.
Углубляться можно до тех пор, пока не закончатся вложенные запросы.
3. Просмотрите список подобранных слов. Поставьте галочки на тех, которые вам подходят, и нажмите «Добавить в медиаплан». Вы можете отметить одновременно запросы из ручного и автоматического подборщиков, и добавить в общий список.
Система просчитает бюджет по ключевым словам. Отчет со списком выбранных слов можно скачать в XLSX-формате. При желании можете продолжить настройку — в этом случае система сгенерирует объявления под каждое ключевое слово.
Проверяем частотности Вордстат
С помощью парсера Вордстат можно проверить частотность для списка запросов.
Откройте страницу парсера. Укажите список запросов в поле «Список фраз для проверки»
Также фразы можно загрузить с помощью XLSX-файла (обратите внимание, все запросы должны находиться на первом листе файла, 1 ячейка — 1 запрос)
Далее задайте настройки парсера:
- широкое соответствие;
- оператор «» (фиксирует количество слов в фразе);
- оператор «кавычки» с восклицательным знаком. Фиксирует количество слов в фразе и словоформу каждого слова;
- оператор [] (квадратные скобки). Используется для фиксации порядка слов в фразе.
Поставьте галочки на нужных параметрах (можете проставить галочки на всех четырех). Затем жмите «Запустить проверку». В течение нескольких минут отчет будет готов, и его можно будет скачать в разделе «Список задач».
Отчет скачивается в формате XLSX-файла. Для каждого запроса в таблице указана частотность. Данные по частотности с учетом операторов поиска указаны в отдельных столбцах. Отфильтруйте список и удалите фразы с околонулевой частотностью.
Вот подробный гайд по работе с парсером Вордстат.
Rush Analytics
Это платный сервис, включающий бесплатный триал на 14 дней, который автоматизирует задачи при парсинге семантического ядра, а именно:
- Проверяет позиции в Яндекс и Google;
- Выполняет кластеризацию запросов;
- Собирает ключевые слова на основе поисковых подсказок;
- Собирает данные из Яндекс.Wordstat в облаке;
- Проверяет индексацию URL;
- Анализирует текст и другие зоны страниц.
С помощью Rush Analytics можно удобно и быстро собрать ключевые слова из Яндекс Wordstat (левой и правой колонок) и Google Рекламы, а также поисковые подсказки.
Всё просто: вы задаете свой запрос, по которому хотите найти похожие, и получаете результаты, вместе с данными по частотности. Без риска «схватить» капчу.
Всё начинаете с создания задачи.
Далее по порядку задаете регион и настройки сбора семантики.
Вы можете собирать ключи из левой и правой колонок или с данными по частотности. Укажите, сколько страниц выдачи Вордстата использовать для сбора запросов. Естественно, чем больше страниц – тем больше результатов.
Если вы выбираете вариант «Сбор частотности», вы можете указать, какой тип частотности вам нужен.
Далее загрузите запросы списком или в виде файла в xls / xlsx.
Также в Rush Analytics есть возможность почистить семантику от стоп-слов – для этого сервис предлагает готовые списки стоп-слов по тематикам.
Когда всё готово, отслеживайте процесс сбора на странице задач.
Кому и зачем следует знать принцип работы Яндекс.Вордстат?
Онлайн-сервис Вордстат – незаменимый помощник для SEO-оптимизаторов и специалистов по контекстной рекламе, продвигающих товары и услуги в Яндекс.Директ.
Работая с Яндекс.Вордстат, вы получите:
- список популярных ключевых запросов для создания рекламной кампании и продвижения веб-ресурса в поисковой выдаче;
- прогноз трафика, анализ частотности показов ключевых слов, соответственно, уровень спроса на тот или иной товар/услугу;
- тренды – запросы пользователей, которые только набирают популярность;
- полезные идеи и помощь при создании новых страниц веб-сайта.
Нужно ли изучать Яндекс.Вордстат владельцам бизнеса, нанимающим вышеперечисленных специалистов? Однозначно – да! Хотя бы поверхностное знание работы сервиса даёт возможность понимать, как и с помощью чего привлекаются новые клиенты. Таким образом, удаётся контролировать работу исполнителей.
Особенно важно тесное сотрудничество между заказчиком и исполнителем при продвижении бизнеса, предлагающего узкоспециализированные товары или услуги. В этом случае, знание и использование отраслевых терминов – верный путь к привлечению постоянных и крупных клиентов
Пошаговая инструкция по работе с Yandex Wordstat
Для грамотного использования Яндекс Вордстат необходимо:
- Зарегистрироваться и войти в свою почту (аккаунт) на Яндексе;
- Записать в поле запрос и кликнуть «Подобрать».
Если вы не залогинились в своем аккаунте, то Yandex Wordstat при заходе в него предложит вам сделать это.
Давайте пробежимся по функционалу интерфейса.
Под основной строкой для ввода ключевого слова есть три флажка:
- «По словам»;
- «По регионам»;
- «История запросов».
Подробнее работу с каждым из них мы рассмотрим далее.
Справа ссылка «Все регионы» — позволит выбрать и посмотреть статистику ключевика по заданному региону.
Сбор запросов по словам
Как видно из вышеприведенного скриншота в Яндекс Вордстат этот вариант стоит «по умолчанию». Он показывает статистику запросов по региону, если тот выбран, если нет, то статистика показывается по всем регионам.
Давайте введем в основное поле фразу «Стройматериалы» и посмотрим, что покажет нам Wordstat. Возможно, вам придется ввести капчу. У меня обошлось без этого.
Система выдаст две колонки, которые будут содержать различные вариации заданного ключевого слова.
В левом столбце Яндекс Вордстат будут все прямые и непрямые вхождения. Правый — отобразит похожие запросы — «стройматериалы», «строительные материалы», «строительный рынок» и т.д. Т.е. отсюда можно выбрать достаточно интересные ключи для продвижения и этим не стоит пренебрегать.
Цифры, расположенные справа от запросов — это количество показов в месяц. Но это всего лишь прогнозируемый Яндексом результат, который вычисляется из статистики поисковика. Т.е. реальный результат может быть больше или меньше прогнозируемого. Но в принципе, плюс/минус Яша всегда показывает «правду».
Еще можно посмотреть статистику отдельно для десктопов, мобильников и т.п., просто переключив флажок в соответствующее поле, под основным полем ввода исследуемой фразы.
Сбор ключевых слов по регионам
При просмотре ключей по регионам на выбор предлагается 3 вкладки:
- Регионы;
- Города;
- Все вместе.
Справа, напротив каждого запроса мы видим соотношение популярности ключа к тому или иному региону. Если кликнуть на соответствующую ссылку, то можно отсортировать запросы по региональной популярности.
Можно посмотреть частотности ключевых слов, показываемые на том или ином устройстве: смартфоне, планшете, ПК и т.д.
Кликнув по вкладке «Карта» откроется интерактивная карта. Наведя мышку на интересующую область, отобразится статистика по этому региону. Желтые области на карте относятся к наиболее популярным, красные к менее популярным.
Как посмотреть историю запросов
Установив флажок в поле «История запросов» можно посмотреть частоту показа этого запроса в определенный период времени (неделя, месяц, год). Таким образом определяются сезонные фразы.
Что это значит? Сезонные запросы – это те запросы, которые пользователи вбивают только в определенное время. Например, фраза «купить велосипед» будет вводиться в поиске Яндекса гораздо чаще весной и летом, чем осенью и зимой. Думаю, что вы со мной согласитесь.
График показывает наглядное изменение количества вводимых фраз за период с 2018 года по 2019. Здесь же можно сделать группировку по неделям и месяцам и выбрать требуемое устройство, как и на предыдущей вкладке.
На графике показаны две кривые – с абсолютным и относительным значениями. Абсолютное показывает значение в данный момент, а относительное – отношение реального количества к общему числу показов за неделю или за месяц. Это общая популярность фразы.
Специальные операторы
Например, вам надо, чтобы сервис показал только определенные фразы в точной словоформе, падеже, числе и тому подобное. Для этого надо обрамить фразу в кавычки и поставить перед каждым словом восклицательный знак. Например, «!жилье !за !границей».
| Оператор | Значение |
| — | Если фраза содержит знак минус, то это слово удаляется. |
|
+ |
Если фраза содержит знак плюс, то показываются только те запросы, которые содержат это слово. |
|
«» |
Фраза в кавычках показывает все слова из данного запросов в любом порядке и словоформе. |
| «!» | Точное вхождение. |
Например, если мы ищем «жилье за -границей», то нам будут показаны только фразы с «жилье за». Слово «граница» не будет учитываться.
Букварикс
Сервис Букварикс предоставляет набор инструментов для работы с ключевыми словами и доменами, а также для работы со списками.
Возможности Букварикс:
- Поиск по ключевым словам (по одному слову или по списку);
- Поиск по заданному домену;
- Сравнение доменов (двух, нескольких).
- Приведение слов в списке к одному виду;
- Анализ слов в списке по частоте встречаемости (в порядке снижения частоты);
- Сравнение двух списков и формирование одного общего списка оригинальных ключевых слов;
- Комбинирование и формирование словосочетаний из ключевых слов двух списков;
- Поиск и удаление дубликатов слов из списка.
Тарифы:
- Без регистрации – бесплатно (с ограниченными возможностями);
- Бесплатный аккаунт – бесплатно (с ограниченными возможностями);
- Бизнес-аккаунт – 695 рублей за 1 месяц.
Яндекс Wordstat
Сервис Яндекс Wordstat предназначен для определения отношения пользователей к тематике сайтов, выявления рекламодателями ключевых слов и формирования ежемесячной статистики ключевых слов Яндекса. Сервис позволяет проводить анализ по частоте и качеству показов рекламных объявлений в Яндекс Директ, а также формировать семантическое ядро.
Возможности Яндекс Wordstat:
- Формирование статистики запросов по заданным ключевым словам или словосочетаниям за месяц или за неделю;
- Формирование статистики запросов на карте;
- Формирование статистики по похожим на заданные слова или словосочетания запросам;
- Формирование статистики запросов по заданным ключевым словам или словосочетаниям в выбранном регионе анализа (продвижения) сайта.
Яндекс Wordstat является бесплатным сервисом.