Изучаем синтаксические парсеры для русского языка
Содержание:
- Поиск «фейловых» ключей (тепловая карта позиций)
- Как работает генератор ключевых слов?
- СловоЁБ — эффективный анализ ключевых слов
- Чек-лист по выбору парсера
- Определение «скрытых» данных на уровне ключевых слов
- Плюсы и минусы работы с Кей Коллектором
- Основные понятия
- Как собирать ключевые слова
- Список имен и фамилий ВК, которые проходят без подтверждения
- Способ 1. Парсим похожие вопросы с выдачи Google
- Подбор ключевых слов Яндекс.Директ в Вордстате
- Парсинг
- Зачем нужен Kparser?
- Программы для подбора и фильтрации запросов
- Три способа записи Windows на флешку
- Парсеры сайтов в зависимости от используемой технологии
- Заключение
- Общие выводы
Поиск «фейловых» ключей (тепловая карта позиций)
Этот инструмент от JSVXC похож на предыдущий, но решает другую задачу. Он помогает найти «фейловые» запросы, по которым сайт недополучает трафик. Фишка инструмента — тепловая карта. С ней удобно ориентироваться в большой массе запросов.
«Фейловыми» можно условно назвать запросы, по которым сайт занимает позиции с 10 по 100. Содержимое сайта обычно релевантно таким запросам, но по какой-то причине поисковики не выводят его в ТОП-10 (проблемы с контентом, внутренней оптимизацией, недостаточный авторитет сайта).
Что нужно для использования тепловой карты:
- создать копию шаблона Content Gap Finder;
- установить дополнение для Google Sheets Search Analytics for Sheets (если вы его установили при работе с предыдущим шаблоном, то повторная установка не требуется);
- иметь доступ к аккаунту в Search Console с данными хотя бы за пару месяцев.
Вначале настраиваем выгрузку данных из Search Console:
- открываем скопированный шаблон и запускаем дополнение Search Analytics for Sheets;
- выбираем сайт, период выгрузки данных, в поле «Group By» указываем «Query» и «Page», в поле «Results Sheet» — «RAW Data»;
Переходим на лист «Content Gaps». Ключи сгруппированы по страницам. По каждому из них отражено количество кликов, показов, CTR и средняя позиция. Цветовая маркировка (тепловая карта) помогает увидеть общую картину и быстро находить нужные ключи.
Таким образом, мы сразу видим, по каким запросам можно «подтянуть» позиции. Как — другой вопрос. Например, недавно мы рассказывали, как отсеошить старый контент и нарастить более чем в 2 раза трафик из SERP.
Как работает генератор ключевых слов?
Генератор ключевых фраз представляет собой автоматизированное решение для создания новых ключевых слов и сочетаний на основе их перемножения в общую фразу. С его помощью построение списка ключевых фраз существенно ускоряется и упрощается. Пересечение слов происходит между всеми указанными столбцами, перечень формируется в режиме реального времени. Идеально подходит для парсинга, для Директа. Увеличение числа колонок, участвующих в пересечении комбинатором, производится простым нажатием на символ “+”. Пересекатор одновременно учитывает данные до 8 столбцов со словами, предельное ограничение числа полученных элементов – 100 000.
СловоЁБ — эффективный анализ ключевых слов
СловоЁБ — это новый программный продукт, позволяющий эффективно парсить и обрабатывать слова. Среди основных инструментов СловоЁБа числятся:
1) парсинг сервиса Yandex.Wordstat: «плоский» и «объемным» поиск;
2) статистика LiveInternet: раскладка по популярности запросов в поисковых системах;
3) позволяет определять целевую страницу под запрос в Яндекс и Гугл.
4) позволяет парсить поисковые подсказки.
5) позволяет парсить конкуренцию.
Программа поддерживает ручную обработку капчи Яндекса, а также работу через прокси-серверы. В качестве альтернативы многопоточности выступает опция «Множитель скорости». Программа автоматически уменьшает время таймаута на количество добавленных прокси-серверов, в результате чего достигается не худшее увеличение скорости обработки данных.
Чек-лист по выбору парсера
Краткий чек-лист, который поможет выбрать наиболее подходящий инструмент или сервис.
- Четко определите, для каких задач вам нужен парсер: анализ SEO конкурентов или мониторинг цен, сбор данных для наполнения каталога, съем позиций и т.д.
- Определите, какой объем данных и в каком виде нужно получать.
- Определите, как часто вам нужно собирать данные: единоразово или с определенной периодичностью (раз в день/неделю/месяц).
- Выберите несколько инструментов, которые подходят для решения ваших задач. Попробуйте демо-версии. Узнайте, предоставляется ли техническая поддержка (желательно даже протестировать ее — задать парочку вопросов и посмотреть, как быстро вы получите ответ и насколько он будет исчерпывающим).
- Выберите наиболее подходящий сервис по соотношению цена/качество.
Для крупных проектов, где требуется парсить большие объемы данных и производить сложную обработку, более выгодной может оказаться разработка собственного парсера под конкретные задачи.
Для большинства же проектов достаточно будет стандартных решений (возможно, вам может быть достаточно бесплатной версии любого из парсеров или пробного периода).
Определение «скрытых» данных на уровне ключевых слов
В Google Analytics есть возможность подгрузить данные из Search Console. Но вы не увидите ничего нового — все те же страницы, CTR, позиции и показы. А было бы интересно посмотреть, какой процент отказов при переходе по тем или иным ключевым словам и, что еще интересней, сколько достигнуто целей по ним.
Тут поможет шаблон от Sarah Lively, который описан в статье для MOZ.
Для начала работы установите дополнения для Google Sheets:
- Google Analytics Spreadsheet Add-on;
- Search Analytics for Sheets (если вы использовали первые два шаблона, то это дополнение у вас уже есть).
Шаг 1. Настраиваем выгрузку данных из Google Analytics
Создайте новую таблицу, откройте меню «Дополнения» / «Google Analytics» и выберите пункт «Create new report».
Заполняем параметры отчета:
- Name — «Organic Landing Pages Last Year»;
- Account — выбираем аккаунт;
- Property — выбираем ресурс;
- View — выбираем представление.
Нажимаем «Create report». Появляется лист «Report Configuration». Вначале он выглядит так:
Но нам нужно, чтобы он выглядел так (параметры выгрузки вводим вручную):
Просто скопируйте и вставьте параметры отчетов (и удалите в поле Limit значение 1000):
| Report Name | Organic Landing Pages Last Year | Organic Landing Pages This Year |
| View ID | //здесь будет ваш ID в GA!!! | //здесь будет ваш ID в GA!!! |
| Start Date | 395daysAgo | 30daysAgo |
| End Date | 365daysAgo | yesterday |
| Metrics | ga:sessions, ga:bounces, ga:goalCompletionsAll | ga:sessions, ga:bounces, ga:goalCompletionsAll |
| Dimensions | ga:landingPagePath | ga:landingPagePath |
| Order | -ga:sessions | -ga:sessions |
| Filters | ||
| Segments | sessions::condition::ga:medium==organic | sessions::condition::ga:medium==organic |
После этого в меню «Дополнения» / «Google Analytics» нажмите «Run reports». Если все хорошо, вы увидите такое сообщение:
Также появится два новых листа с названиями отчетов.
Шаг 2. Выгрузка данных из Search Console
Работаем в том же файле. Переходим на новый лист и запускаем дополнение Search Analytics for Sheets.
Параметры выгрузки:
- Verified Site — указываем сайт;
- Date Range — задаем тот же период, что и в отчете «Organic Landing Pages This Year» (в нашем случае — последний месяц);
- Group By — «Query», «Page»;
- Aggregation Type — «By Page»;
- Results Sheet — выбираем текущий «Лист 1».
Выгружаем данные и переименовываем «Лист 1» на «Search Console Data». Получаем такую таблицу:
Для приведения данных в сопоставимый с Google Analytics вид меняем URL на относительные — удаляем название домена (через функцию замены меняем домен на пустой символ).
После изменения URL должны иметь такой вид:
Шаг 3. Сводим данные из Google Analytics и Search Console
Копируем шаблон Keyword Level Data. Открываем его и копируем лист «Keyword Data» в наш рабочий файл. В столбцы «Page URL #1» и «Page URL #2» вставляем относительные URL страниц, по которым хотим сравнить статистику.
По каждой странице подтягивается статистика из Google Analytics, а также 6 самых популярных ключей, по которым были переходы. Конечно, это не детальная статистика по каждому ключу, но все же это лучше, чем ничего.
При необходимости вы можете доработать шаблон — изменить показатели, количество выгружаемых ключей и т. п. Как это сделать, детально описано в оригинальной статье.
Как видите, для работы с ключами не обязательно сразу доставать кошелек. Есть немало простых решений. Следите за нашими публикациями — мы еще не раз поделимся полезностями.
Плюсы и минусы работы с Кей Коллектором
Еще один вариант – сбор парсером KeyCollector (КК). Эта программа покупается один раз, причем по вполне сходной и доступной цене, а затем используем бесплатно.

При больших объемах КК очень сильно подгружает Ваш ПК, да и скорость сбора данных у него низкая. Поэтому мощность компьютера, на котором Вы хотите парсить большие объемы должна быть соответствующей.
Для настройки многих операций сбора КК может потребовать определенных умственных усилий и хлопот при подключение разных аккаунтов, прокси-серверов, работе с капчей и т.п.
Но без этого получить данные без ощутимых материальных затрат не получится.
Я использую KeyCollector при работе над СЯ в основном на этапе чистки собранных ключей от мусора, дублей и т.п..
Основные понятия
- входной символьный поток (далее входной поток или поток) — поток символов для разбора, подаваемый на вход парсера
- parser/парсер (разборщик, анализатор) — программа, принимающая входной поток и преобразующая его в AST и/или позволяющая привязать исполняемые функции к элементам грамматики
- AST(Abstract Syntax Tree)/АСД(Абстрактное синтаксическое дерево) (выходная структура данных) — Структура объектов, представляющая иерархию нетерминальных сущностей грамматики разбираемого потока и составляющих их терминалов. Например, алгебраический поток (1 + 2) + 3 можно представить в виде ВЫРАЖЕНИЕ(ВЫРАЖЕНИЕ(ЧИСЛО(1) ОПЕРАТОР(+) ЧИСЛО(2)) ОПЕРАТОР(+) ЧИСЛО(3)). Как правило, потом это дерево как-то обрабатывается клиентом парсера для получения результатов (например, подсчета ответа данного выражения)
- CFG(Context-free grammar)/КСГ(Контекстно-свободная грамматика) — вид наиболее распространенной грамматики, используемый для описания входящего потока символов для парсера (не только для этого, разумеется). Характеризуется тем, что использование её правил не зависит от контекста (что не исключает того, что она в некотором роде задает себе контекст сама, например правило для вызова функции не будет иметь значения, если находится внутри фрагмента потока, описываемого правилом комментария). Состоит из правил продукции, заданных для терминальных и не терминальных символов.
- Терминальные символы (терминалы) — для заданного языка разбора — набор всех (атомарных) символов, которые могут встречаться во входящем потоке
- Не терминальные символы (не терминалы) — для заданного языка разбора — набор всех символов, не встречающихся во входном потоке, но участвующих в правилах грамматики.
- язык разбора (в большинстве случаев будет КСЯ(контекстно-свободный язык)) — совокупность всех терминальных и не терминальных символов, а также КСГ для данного входного потока. Для примера, в естественных языках терминальными символами будут все буквы, цифры и знаки препинания, используемые языком, не терминалами будут слова и предложения (и другие конструкции, вроде подлежащего, сказуемого, глаголов, наречий и т.п.), а грамматикой собственно грамматика языка.
-
BNF(Backus-Naur Form, Backus normal form)/БНФ(Бэкуса-Наура форма) — форма, в которой одни синтаксические категории последовательно определяются через другие. Форма представления КСГ, часто используемая непосредственно для задания входа парсеру. Характеризуется тем, что определяемым является всегда ОДИН нетерминальный символ. Классической является форма записи вида:
Так же существует ряд разновидностей, таких как ABNF(AugmentedBNF), EBNF(ExtendedBNF) и др. В общем, эти формы несколько расширяют синтаксис обычной записи BNF. - LL(k), LR(k), SLR,… — виды алгоритмов парсеров. В этой статье мы не будем подробно на них останавливаться, если кого-то заинтересовало, внизу я дам несколько ссылок на материал, из которого можно о них узнать. Однако остановимся подробнее на другом аспекте, на грамматиках парсеров. Грамматика LL/LR групп парсеров является BNF, это верно. Но верно также, что не всякая грамматика BNF является также LL(k) или LR(k). Да и вообще, что значит буква k в записи LL/LR(k)? Она означает, что для разбора грамматики требуется заглянуть вперед максимум на k терминальных символов по потоку. То есть для разбора (0) грамматики требуется знать только текущий символ. Для (1) — требуется знать текущий и 1 следующий символ. Для (2) — текущий и 2 следующих и т.д. Немного подробнее о выборе/составлении BNF для конкретного парсера поговорим ниже.
- PEG(Parsing expression grammar)/РВ-грамматика — грамматика, созданная для распознавания строк в языке. Примером такой грамматики для алгебраических действий +, -, *, / для неотрицательных чисел является:
Как собирать ключевые слова
Для Рунета основным источником ключевых слов является сервис Wordstat от ПС Яндекс.
Запросов от Google, как правило, получается гораздо меньше и поэтому они чаще используются на этапе сбора базовых запросов. Как результат, в подавляющем большинстве случаев парсят Вордстат и этого бывает вполне достаточно.
Если же у Вас какая-то узкая ниша и надо обеспечивать максимальную полноту, тогда можно подключать сервисы Google и/или базы запросов.
Процедура парсинга запросов в облачных сервисах проходит довольно просто. Например, для Rush-Analytics необходимо задавать следующие параметры:
- Настроить проект в сервисе.
- Установить региональность.
- Выбрать пункт «Собрать ключевые слова».
- Загрузить список Базовых Запросов.
- Загрузить список минус-слов, если они у Вас уже есть.
- Инициировать работу парсера по сбору ключевых фраз.
Более наглядно этот процесс можно увидеть в этом небольшом видеоролике.
У меня первый прогон обычно используется для формирования списка минус слов. Выгружаю полученный результат и методом пристального взора составляю список таких слов.
Второй прогон, с учетом собранных минусов, уже будет более результативным и список ключей будет содержать гораздо меньше мусорных запросов. Тем не менее мы опять просматриваем полученные ключи, чистим мусор, пополняем список минус-слов и у нас все готово для следующего шага — сбора подсказок.
Список имен и фамилий ВК, которые проходят без подтверждения
Вот список мужских и женских имен, которые ты можешь использовать чтобы изменить имя без отправки заявки на модерацию.
Ниже списка имен я выложил список подобранных экспериментальным способом фамилий, которые также проходят в ВК без модерации.
Пользуйтесь.
В качестве благодарности, оставьте комментарий под этой статьей.
О том, как использовать этот список, чтобы изменить имя и фамилию в ВК без проверки администратора читайте здесь.
| Фамилии, подходящие как для парней так и для девушек: | Женскиеимена: | Мужскиеимена: |
|---|---|---|
| Аксенова | Александра | Валентин |
| Андреев | Алина | Валерий |
| Быков | Алиса | Вячеслав |
| Васильев | Анастасия | Глеб |
| Виноградов | Ангелина | Даниил |
| Голубев | Анжела | Егор |
| Голубь | Богдана | Иван |
| Гусев | Валентина | Мирон |
| Гусь | Валерия | Мирослав |
| Дёмин | Варвара | Мурат |
| Зайцев | Вероника | Назар |
| Иванов | Виктория | Никита |
| Колесников | Вита | Николай |
| Корнеев | Дарья | Петр |
| Котов | Диана | Ростислав |
| Крот | Дина | Станислав |
| Куликов | Динара | Степан |
| Курочкин | Екатерина | Тимур |
| Макаров | Елена | Филипп |
| Максимов | Жанна | Ярослав |
| Маликова | Зинаида | |
| Мальцева | Злата | |
| Маркелова | Зоя | |
| Никитина | Инна | |
| Петрова | Ирина | |
| Семёнова | Кристина | |
| Сова | Лариса | |
| Соколова | Леся | |
| Тихонова | Лилия | |
| Филатова | Лолита | |
| Холод | Любовь | |
| Царь | Людмила | |
| Шабанова | Маргарита | |
| Юсупова | Марианна | |
| Аксенова | Марина | |
| Андреева | Милена | |
| Быкова | Рада | |
| Васильева | Юлия |
Как пользоваться этой таблицей:
https://youtube.com/watch?v=jzoSoqEhVGo
Полный список мужских имен Вк:
Азамат
Азат
Александр
Алексей
Альберт
Анатолий
Андрей
Антон
Артём
Аркадий
Арсений
Артур
Богдан
Борис
Валерий
Валентин
Василий
Вадим
Владимир
Владислав
Виктор
Виталий
Вячеслав
Григорий
Глеб
Герман
Георгий
Геннадий
Давид
Даниил
Дмитрий
Денис
Евгений
Егор
Захар
Иван
Игорь
Ильдар
Илья
Кирилл
Константин
Леонид
Марат
Марк
Максим
Михаил
Назар
Никита
Николай
Олег
Павел
Пётр
Рашид
Ринат
Роберт
Роман
Руслан
Рустам
Святослав
Станислав
Степан
Сергей
Семён
Тарас
Тимофей
Филипп
Фёдор
Эрик
Эльдар
Эмиль
Эдуард
Юрий
Ярослав
Яков
Полный список женских имен Вконтакте:
Алевтина
Александра
Алёна
Алина
Алиса
Алия
Алла
Алсу
Альбина
Анастасия
Ангелина
Анжелика
Анна
Антонина
Арина
Ася
Валентина
Валерия
Варвара
Василиса
Вера
Вероника
Виктория
Виолетта
Виталия
Владислава (Влада)
Галина
Гузель
Гульнара (Гульназ, Гуля)
Дана
Дарья
Диана
Дина
Динара
Ева
Евгения
Екатерина
Елена
Елизавета
Жанна
Зарина
Земфира
Зинаида
Зоя
Иванна
Изабелла
Илона
Инга
Инесса
Инна
Ирина
Камилла
Кира
Карина
Каролина
Кристина
Ксения
Лариса
Леся
Лиана
Лидия
Лилия
Лина
Лолита
Любовь
Людмила
Мадина
Майя
Маргарита
Марина
Мария
Марта
Мила
Милана
Милена
Марианна
Мирослава
Марьяна
Надежда
Наталья
Нина
Нелли
Нонна
Оксана
Олеся
Ольга
Полина
Раиса
Регина
Римма
Роза
Руслана
Сабина
Светлана
Снежана
Софья
Таисия (Тая, Тася)
Тамара
Татьяна
Ульяна
Элина
Эльвира
Юлия
Яна
Способ 1. Парсим похожие вопросы с выдачи Google
Введите в поиске Google любой информационный запрос. Например, в формате «как сделать…». В выдаче, скорее всего, кроме обычных сниппетов появится блок с похожими вопросами. Выглядит он вот так:
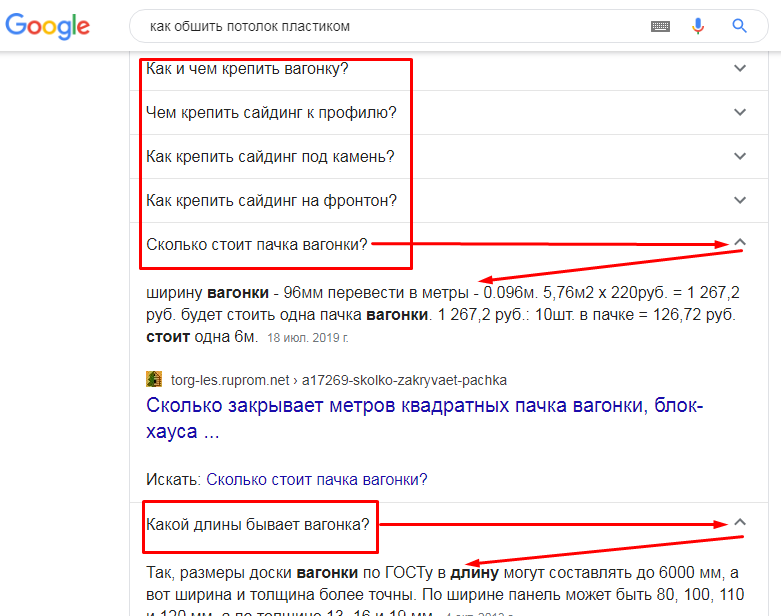
При клике по любому вопросу он раскрывается, отображается ответ (релевантный фрагмент контента) и ссылка на страницу, откуда этот ответ взят.
Также при раскрытии одного вопроса ниже появляются новые вопросы. Соответственно, чем больше вопросов вы раскроете, тем больше появится новых вопросов и ответов.
Что с этим делать?
«Похожие вопросы» — тот самый источник низкочастотных запросов, о котором могут не догадываться ваши конкуренты. Алгоритм работы такой:
- Открыть как можно больше вопросов (чтобы подгрузились новые и список был больше).
- Собрать вопросы в файл.
- Оптимизировать под них существующий контент на сайте или создать новые страницы.
Собрать вопросы можно вручную: раскрыть как можно больше, выделить их, затем скопировать и вставить в Google Таблицы или Excel. Минус такого способа скопируется лишний контент (ссылки и картинки).
Такую табличку нужно будет почистить от ненужного контента, чтобы остались только вопросы.
Но проще спарсить вопросы с помощью Xpath-парсера. Если вы не знакомы с Xpath, это не проблема. Это специальный язык запросов, с помощью которых можно извлечь содержимое любого html или xml документа. Для парсинга вопросов, на самом деле, о Xpath больше знать ничего и не нужно. Но если хотите узнать больше о синтаксисе языка и возможностях использования, почитайте документацию.
Сбор запросов с помощью Xpath-парсера

Откройте все вопросы, которые показываются в блоке изначально, а затем откройте новые вопросы, которые появились после открытия первых.
Не ограничивайте себя: откройте максимальное количество вопросов – чем больше, тем лучше. Удобнее всего начать с нижних вопросов и открывать их снизу вверх.

4. Кликните по иконке Scraper’а, в меню расширения выберите пункт «Scrape similar…».
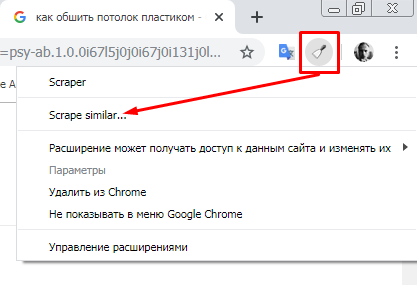
5. Откроется окно парсера. В блоке Selector выберите Xpath в выпадающем списке, а в поле справа введите «//g-accordion-expander».
Обратите также внимание на блок «Column». Заполните его так, как показано на скриншоте:

Затем нажмите кнопку «Scrape».
В правой области окна появятся данные, которые собрал парсер. Теперь их нужно привести в удобный для использования вид. Если мы их в таком виде вставим в Excel, работать с ними будет достаточно непросто:

С таким текстом можно справиться с помощью формул: разбить текст на колонки и затем взять только вопросы.
Но нет смысла ломать голову, так как есть готовое решение. Для этого нужны Google Таблицы и этот шаблон. Откройте шаблон и нажмите «Файл → Создать копию».
Откройте копию и перейдите на лист «Google Questions and Answers».
Дальше последовательность действий такая:
-
В интерфейсе парсера (Scraper) кликаем по кнопке «Copy to clipboard».
-
Переходим в таблицу с шаблоном и устанавливаем курсор в ячейку А10 (с содержимым «Text»).
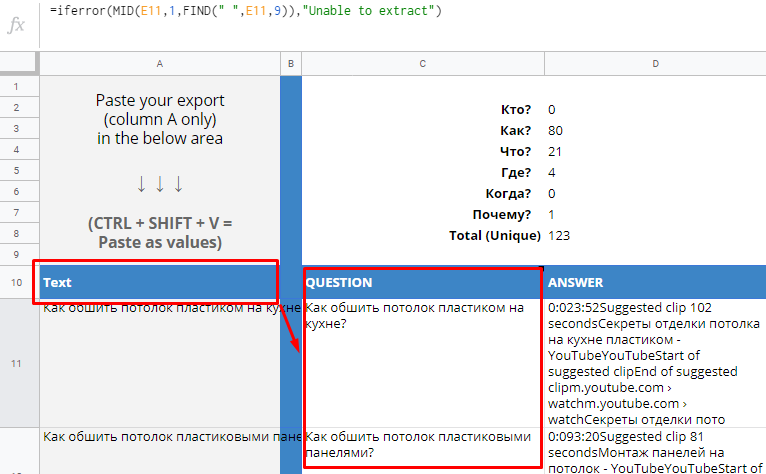
-
Нажимаем сочетание клавиш Ctrl+Shift+V. Собранные парсером значения будут вставлены в первый столбец таблицы, а в остальных столбцах формулы разобьют сплошной текст на фрагменты (вопрос, ответ и другие).
-
Открываем лист «Clean Data» – в столбце «Question» будет список вопросов, очищенный от дубликатов. Копируем список и вставляем его в отдельную таблицу или текстовый файл.

Обратите внимание! После такой процедуры у вас на руках не только список перспективных НЧ-запросов, но и практически готовый контент-план для статей
Подбор ключевых слов Яндекс.Директ в Вордстате
Подбор ключевых слов для Яндекс Директ осуществляется на основе статистики запросов поисковой системы Яндекс. Эта статистика доступна в сервисе Яндекс.Вордстат — https://wordstat.yandex.ru/. Здесь можно найти статистику запросов за последний месяц или любой другой промежуток времени. Посмотреть статистику ключевых слов в отдельных регионах и городах, а также по типам устройств.
Рассмотрим по шагам, как работать с сервисом.
Шаг 1. В поисковую строку введите основной вид деятельности Вашего бизнеса. Например, если компания занимается малоэтажным строительством, то нужно ввести или .
Подбор ключевиков по регионам

Шаг 2. Чтобы посмотреть статистику по региону, в котором Вы работаете — выберите «Все регионы», отметьте свой регион или город, а затем подтвердите свой выбор, нажав «Выбрать».
Вы увидите подробную статистику по ключевым запросам за последний месяц в нашем регионе. Остаётся собрать ключевые слова. Для этого мы рекомендуем использовать плагин Yandex Wordstat Helper для бразуера. Он поможет быстро выбирать нужные ключевые слова для нашей рекламной кампании и рядом с запросами, у Вас будут отображаться плюсики. Нажимая на «плюсик» рядом с ключевым слово, Вы даёте указание плагину запомнить его.

Пройдитесь по нескольким страницам статистики и отберите ключевые слова, по которым Вы бы хотели рекламироваться, при этом отсеивая ненужные: или . Такие запросы вводят не клиенты, а соискатель рабочего места.
После того, как Вы отобрали необходимый перечень ключевых слов, нажмите кнопочку «Копировать в буфер обмена», а затем вставьте их в экселевскую таблицу.

Задайте вопрос себе и своим сотрудникам, как Вас ещё могут искать пользователи в сети? Проведите мозговой штурм. Ведь сколько людей, столько и мнений. Проанализируйте, какие синонимы могут быть у тех ключевых слов, которые Вы уже отобрали. Например, кто-то может искать или , а ведь они тоже могут являться Вашими клиентами. Следует учесть и то, что человек вообще может не упомянуть какое-то из ключевых слов в запросе и ввести скажем , тем самым также подразумевая строительство.
Здесь, мы специально выбрали строительную тематику, чтобы наглядно показать, насколько различными могут быть запросы клиентов. Да, в некоторых случаях, они могут ограничиться несколькими сотнями, а в других и 50000 будет казаться мало. Именно, поэтому так важен правильный подбор ключевых слов для Яндекс Директ.
Как проверить частотность ключевых слов
Шаг 3. Перед использованием собранных слов, их нужно очистить от мусорных запросов или запросов пустышек. «Пустышки» — запросы, которые используются в составе других запросов, но не используются отдельно.
Берём фразу . По данным сервиса она используется 219 376 раз в месяц.

Проверяем фразу, для этого ставим её в кавычки и перед каждым слов без пробела пишем восклицательный знак . И видим, что реальных запросов гораздо меньше.

Это так называемая проверка частотности ключевых слов. Минус подхода в том, что каждый ключевик нужно проверять отдельно. Если у вас небольшой объём семантики, до 100 ключевых слов, то можно сделать это вручную. В остальных случаях рекомендуем использовать онлайн-сервисы для парсинга, о которых мы расскажем ниже.
Шаг 4. Все отобранные нами ключевые слова, Вы можете использовать при создании своих рекламных объявлений. Для одного рекламного объявления можно задать до 200 ключевых слов по которым оно будет показываться.

Подробнее: Настройка рекламы Яндекс.Директ
Парсинг
После составления масок, их необходимо «распарсить», т.е. собрать список ключевых запросов, которые образовываются с помощью наших масок. Эти запросы также называют «хвостом».
Для парсинга мы используем Кей Коллектор. Это программа, которая создана специально для работы с семантическим ядром. Она платная, но на сегодня это лучший инструмент для работы с СЯ.
Если вы настраиваете кампании только для себя, возможно, нет смысла покупать ее. В таком случае можете попробовать ее бесплатный аналог «Словоеб» или собрать запросы в ручную с помощью Wordstat или инструмента для работы с ключевыми словами от Google Ads.
Чистка списка фраз
После парсинга, в зависимости от ниши, мы могли получить несколько тысяч или даже десяток тысяч ключевых слов. Но подходит нам только часть этих фраз.
Чтобы не показывать рекламу незаинтересованным пользователям и не сливать рекламный бюджет в пустую, нам необходимо собрать список минус-слов, которые будут блокировать рекламу по неподходящим нам запросам.
Например, если вы распарсили запрос ремонт квартир, то там будут такие запросы, как ремонт квартир своими руками или ремонт квартир книги. Своими руками и книга говорят о том, что человек не собирается заказывать услуги, а хочет сделать ремонт самостоятельно, поэтому нам нет смысла показывать им рекламу. Мы добавляем эти слова в список минус-слов.
Околоцелевы запросы
Например, вы продаете детские коляски. Ваша целевая аудитория — молодые мамы. Вы начинаете думать, что могут искать молодые мамы в интернете и добавляете такие фразы: детская кроватка, автокресла, комбинезон для новорожденного и т.д.
В теории такой подход может сработать, но есть нюансы:
1) за эти запросы тоже конкурируют рекламодатели и они могут быть дороже, чем ваши целевые запросы; 2) ваша реклама будет нерелевантной – человек интересуется детской одеждой, а вы ему предлагаете купить коляску. На поиске Google и Яндекс кликов будет мало и они будут дорогие. В РСЯ, как показывает опыт, также будет мало показов, низкий CTR и низкая конверсия.
Такие запросы можно протестировать, если вы уже используете основные источники трафика, но вам этого мало и хотите расширяться.
Информационные запросы
Перед покупкой товара или заказом услуги люди проходят разные этапы заинтересованности. Например, перед тем, как купить кроссовки для бега, человек может искать информацию в интернете, как правильно выбрать кроссовки для бега, а перед покупкой нового матраса — информацию об улучшении качестве сна.
С помощью контекстной рекламы мы можем обращаться к пользователям на разных этапах принятия решения. Но будет большой ошибкой пытаться продавать им «в лоб» и вести их сразу на страницу товара или услуги. Скорее всего, они ничего не закажут, а просто закроют сайт.
Чтобы реклама на околоцелевые запросы дала результаты, нужно подготовить релевантные и интересные для пользователей страницы, с которых вы уже будете вести их вниз по воронке продаж.
Зачем нужен Kparser?
На официальном сайте найдете несколько полезных статей с описанием способов применения Kparser. Например:
- В Youtube — осуществляет подбор тегов и ключевых слов с «длинным хвостом» для видео, которые бы отлично охарактеризовали ролик и были максимально эффективны с точки зрения продвижения.
- Google — сбор подсказок под SEO и Adwords. Используя совместно сервисы Adwords Keyword Tool и Kparser, вы достигнете лучшего результата по выборке. Причем последний выдает в разы больше информации + доступен всем пользователями.
- Google Search Console — соединение данных из двух инструментов позволит улучшить показатели органического трафа. Собирайте релевантные подсказки для тайтлов/текстов имеющихся страниц либо делайте новые под ключевые запросы с хорошим потенциалом.
- Определяйте минус слова под ваши Adwords и Direct кампании.
- Google Search Trends — ищите трендовые направления для создания актуального контента + формируйте через Kparser фразы с длинным хвостом.
- eBay + Amazon — по аналогии с Youtube и другими нишевыми продуктами рассматриваемый проект помогает определять релевантные ключи и поднять ваш товар повыше в выдаче.
Советую хорошенько изучить все эти инструкции, т.к. там весьма детально рассмотрены ситуации, в которых Kparser позволит выжать максимум из того или иного сервиса. К сожалению, пока что информация представлена только на английском.
Возьмем к примеру Youtube…
По правилам хорошей оптимизации ролика вам нужно:
- придумать наиболее релевантный ключевой запрос для видео;
- использовать его в имени загружаемого файла, заголовке и других элементах на странице;
- создать хорошее описание с вашими ключевиками и похожими по смыслу фразами;
- добавить запросы в теги, по которым должны находить данное видео;
- напоследок поделитесь роликом во всех своих социальных аккаунтах и, возможно, попросите об этом друзей либо закажите небольшую рекламу — надо постараться сделать своего рода вирусный эффект после публикации.
Теги для видоса — очень важны. Если их не указываете, то получите нулевую оценку параметра vidIQ. С заполненными полями результат явно получше:
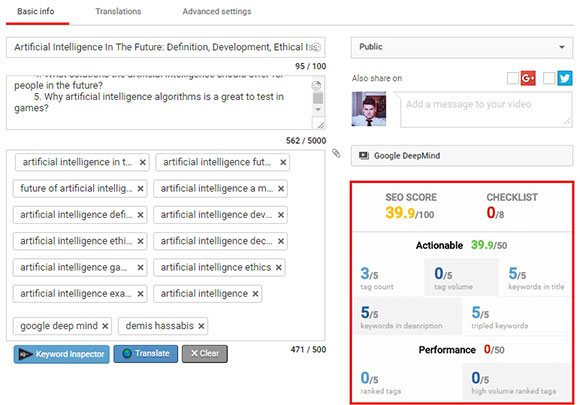
Теги добавляются дабы поисковики понимали о чем ваше видео и, соответственно, по каким запросам в Youtube оно будет ранжироваться.
Если у вас новый канал, старайтесь использовать менее конкурентные ключевики с длинным хвостом — так больше шансов побороться за трафик. Популярным авторам есть смысл вклиниться в борьбу по крутым тегам. Найти подходящие варианты вам как раз и поможет текущий инструмент.
Программы для подбора и фильтрации запросов
- Key Collector — по признанию многих оптимизаторов — это лучшая программа для составления семантического ядра;
- Словоеб — младший брат Key Collector;
- Allsubmitter — многофункциональная программа, при помощи которой можно подбирать ключевые слова;
- Магадан — парсер ключевых слов Яндекс.Директа;
- Key Hunter — поиск и парсинг открытых Яндекс.Метрик;
- Metrica Spy — поиск и парсинг открытых Яндекс.Метрик, обсуждение;
- МегаЛемма — софт для морфологической обработки массивов ключевых слов и дальнейшей группировки;
- YWSCheck — парсер Яндекс.Вордстат и Яндекс.Директ;
- Yandex Key Checker — программа проверки ключей в Яндексе на частоту и конкурентность;
- Букварикс — программа для быстрого подбора ключевых слов, обсуждение;
- YaLiPa — парсер прямого эфира Яндекс;
- Kolyan — парсер прямого эфира Яндекс;
Три способа записи Windows на флешку
Парсеры сайтов в зависимости от используемой технологии
Парсеры на основе Python и PHP
Такие парсеры создают программисты. Без специальных знаний сделать парсер самостоятельно не получится. На сегодня самый популярный язык для создания таких программ Python. Разработчикам, которые им владеют, могут быть полезны:
- библиотека Beautiful Soup;
- фреймворки с открытым исходным кодом Scrapy, Grab и другие.
Заказывать разработку парсера с нуля стоит только для нестандартных задач. Для большинства целей можно подобрать готовые решения.
Парсеры-расширения для браузеров
Парсить данные с сайтов могут бесплатные расширения для браузеров. Они извлекают данные из html-кода страниц при помощи языка запросов Xpath и выгружают их в удобные для дальнейшей работы форматы — XLSX, CSV, XML, JSON, Google Таблицы и другие. Так можно собрать цены, описания товаров, новости, отзывы и другие типы данных.
Примеры расширений для Chrome: Parsers, Scraper, Data Scraper, kimono.
Парсеры сайтов на основе Excel
В таких программах парсинг с последующей выгрузкой данных в форматы XLS* и CSV реализован при помощи макросов — специальных команд для автоматизации действий в MS Excel. Пример такой программы — ParserOK. Бесплатная пробная версия ограничена периодом в 10 дней.
Парсинг при помощи Google Таблиц
В Google Таблицах парсить данные можно при помощи двух функций — importxml и importhtml.
Функция IMPORTXML импортирует данные из источников формата XML, HTML, CSV, TSV, RSS, ATOM XML в ячейки таблицы при помощи запросов Xpath. Синтаксис функции:
IMPORTXML("https://site.com/catalog"; "//a/@href")
IMPORTXML(A2; B2)
Расшифруем: в первой строке содержится заключенный в кавычки url (обязательно с указанием протокола) и запрос Xpath.
Знание языка запросов Xpath для использования функции не обязательно, можно воспользоваться опцией браузера «копировать Xpath»:
Вторая строка указывает ячейки, куда будут импортированы данные.
IMPORTXML можно использовать для сбора метатегов и заголовков, количества внешних ссылок со страницы, количества товаров на странице категории и других данных.
У IMPORTHTML более узкий функционал — она импортирует данные из таблиц и списков, размещенных на странице сайта. Синтаксис функции:
IMPORTHTML("https://https://site.com/catalog/sweets"; "table"; 4)
IMPORTHTML(A2; B2; C2)
Расшифруем: в первой строке, как и в предыдущем случае, содержится заключенный в кавычки URL (обязательно с указанием протокола), затем параметр «table», если хотите получить данные из таблицы, или «list», если из списка. Числовое значение (индекс) означает порядковый номер таблицы или списка в html-коде страницы.
Заключение
Вот мы и рассмотрели, как подключить монитор к ноутбуку. Надеюсь, что эта информация оказалась для вас полезной.
Общие выводы
- Не так страшен чёрт, как его малюют. Создание парсера с помощью инструмента, дело, в общем, посильное. Достаточно изучить общие принципы и потратить полдня на изучение конкретного инструмента, после чего в дальнейшем все уже будет намного проще. А вот велосипеды изобретать — не надо. Особенно, если вам не особенно важна скорость парсинга и оптимизации.
- Грамматики имеют собственную ценность. Имея перед глазами грамматику, гораздо проще оценить, будут ли при использовании составленного по ней парсера возникать ошибки.
- Инструмент можно найти всегда. Возможно, не на самом привычном языке, но почти на всех они есть. Если не повезло, и его все-таки нет, можно взять что-нибудь легко используемое (что-то на js, python, lua или ruby — тут уж кому что больше нравится). Да, получится “почти stand-alone в рамках проекта”, но в большинстве случаев этого достаточно.
- Все инструменты (немного) различаются. Иногда это “:” вместо “=” в BNF, иногда различия более обширны. Не надо этого пугаться. В крайнем случае, переделка грамматики под другой инструмент займет у вас минут 20. Так что если есть возможность достать где-то грамматику, а не писать её самому, лучше это сделать. Но перед использованием все равно лучше её проверьте. Все мы люди, всем нам свойственно ошибаться…
- При прочих равных, лучше используйте более “разговорчивый” инструмент. Это поможет избежать ошибок составления грамматики и оценить, что и как будет происходить.
- Если для вас в первую очередь важна скорость разбора, боюсь, вам придется либо пользоваться инструментом для C (например, Bison), либо решать проблему “в лоб”. Так же, следует задуматься о том, нужен ли вам именно парсинг (об этом стоит задуматься в любом случае, но в случае скоростных ограничений — особенно). В частности, для многих задач подходит токенизация — разбиение строки на подстроки с использованием заданного разделителя или их набора. Возможно, это ваш случай.