7 linux grep or, grep and, grep not operator examples
Содержание:
- Популярные теги
- Примеры использования регулярных выражений
- Об авторах
- Основные команды Sed
- Замена слова в файле
- Замена слова в файле и вывод результата в другой файл
- Замена слова в нескольких файлах одновременно
- Отбросить всё, что левее определённого слова
- Отбросить всё, что правее определённого слова
- Экранирование символов в sed
- Два условия одновременно в Sed
- Удалить строку
- Получить диапазон строк
- Использование регулярных выражений
- Применение grep в Linux
- 2. Примеры использования команды Grep
- 10. Как работать с файлами с помощью команды Tree в Linux
- файлов grep и регулярные выражения
- EXAMPLE top
- Context line control
- Technical description
- Синтаксис и опции less
- Example usage
Популярные теги
ubuntu
linux
ubuntu_18_04
settings
debian
setup
ubuntu_16_04
error
macos
redhat
problems
mint
windows
install
server
ubuntu_18_10
desktop
update
android
bash
wifi
hardware
убунту
files
rhel
network
web
docker
kali
security
windows_10
nvidia
ustanovka
apt
filesystem
python
software
stretch
issues
kde
password
apache2
manjaro
mysql
wine
program
video_card
for
disk
shell
apt-get
drivers
partition
performance
vpn
gnome
keyboard
terminal
kubuntu
usb
ubuntu_20_04
package-management
video
driver
games
wi_fi
nginx
best
installation
sound
delete
user
macbook
disk_space
freebsd
dual_boot
virtualbox
ubuntu_17_10
cron
fedora
lubuntu
oshibka
chrome
boot
scripting
ssh
mail
os
centos
zorin_os
command-line
firewall
git
tools
zorin
bluetooth
hotkeys
kvm
kernel
display
Примеры использования регулярных выражений
Теперь, когда мы рассмотрели основы и вы знаете как все работает, осталось закрепить полученные знания про регулярные выражения linux grep на практике. Два очень полезные спецсимвола — это ^ и $, которые обозначают начало и конец строки. Например, мы хотим получить всех пользователей, зарегистрированных в нашей системе, имя которых начинается на s. Тогда можно применить регулярное выражение «^s». Вы можете использовать команду egrep:
Если мы хотим отбирать строки по последнему символу в строке, что для этого можно использовать $. Например, выберем всех системных пользователей, без оболочки, записи о таких пользователях заканчиваются на false:
Чтобы вывести имена пользователей, которые начинаются на s или d используйте такое выражение:
Такой же результат можно получить, использовав символ «|». Первый вариант более пригоден для диапазонов, а второй чаще применяется для обычных или/или:
Теперь давайте выберем всех пользователей, длина имени которых составляет не три символа. Имя пользователя завершается двоеточием. Мы можем сказать, что оно может содержать любой буквенный символ, который должен быть повторен три раза, перед двоеточием:
Об авторах
Daniel Robbins
Дэниэль Роббинс — основатель сообщества Gentoo и создатель операционной системы Gentoo Linux. Дэниэль проживает в Нью-Мехико со свой женой Мэри и двумя энергичными дочерьми. Он также основатель и глава Funtoo, написал множество технических статей для IBM developerWorks, Intel Developer Services и C/C++ Users Journal.
Chris Houser
Крис Хаусер был сторонником UNIX c 1994 года, когда присоединился к команде администраторов университета Тэйлора (Индиана, США), где получил степень бакалавра в компьютерных науках и математике. После он работал во множестве областей, включая веб-приложения, редактирование видео, драйвера для UNIX и криптографическую защиту. В настоящий момент работает в Sentry Data Systems. Крис также сделал вклад во множество свободных проектов, таких как Gentoo Linux и Clojure, стал соавтором книги The Joy of Clojure.
Aron Griffis
Эйрон Гриффис живет на территории Бостона, где провел последнее десятилетие работая в Hewlett-Packard над такими проектами, как сетевые UNIX-драйвера для Tru64, сертификация безопасности Linux, Xen и KVM виртуализация, и самое последнее — платформа HP ePrint. В свободное от программирования время Эйрон предпочитает размыщлять над проблемами программирования катаясь на своем велосипеде, жонглируя битами, или болея за бостонскую профессиональную бейсбольную команду «Красные Носки».
Основные команды Sed
Для того чтобы применить SED достаточно ввести в командную строку
echo ice | sed s/ice/fire/
Результат:
fire
Замена слова в файле
Обычно SED применяют к файлам, например к логам или конфигам.
Предположим, что у нас есть файл input.txt следующего содержания
Мы хотим заменить слово Here на There
sed ‘s/HereThere/’ input.txt
Результат будет выведен в консоль:
There is a String
There is an Integer
There is a Float
Если нужно не вывести в консоль а изменить содержание файла — используем опцию -i
sed -i ‘s/HereThere/’ input.txt
В этом случае перепишется исходный файл input.txt
Рассмотрим пример посложнее. Файл input.txt теперь выглядит так:
sed ‘s/HereThere/’ input.txt
Как Вы сейчас увидите, замена произойдёт только по одному разу в строке
There is an Apple. Here is a Pen. Here is an ApplePen
Integer is There
There is a Float
There is a Pen. Here is a Pineapple. Here is a PineapplePen
Чтобы заменить все слова нужна опция g
sed ‘s/HereThere/g’ input.txt
There is an Apple. There is a Pen. There is an ApplePen
Integer is There
There is a Float
There is a Pen. There is a Pineapple. There is a PineapplePen

Замена слова в файле и вывод результата в другой файл
Та же замена, но с выводом в новый текстовый файл, который мы назовём output:
sed ‘s/HereThere/’ input.txt > output.txt
Замена слова в нескольких файлах одновременно
Если нужно обработать сразу несколько файлов: например файл 1.txt с содержанием
И файл 2.txt с содержанием
Это можно сделать используя *.txt
sed ‘s/HereThere/’ *.txt > output.txt
На выходе файл output.txt будет выглядеть так
Отбросить всё, что левее определённого слова
Предположим, что у нас есть файл input.txt следующего содержания
Мы хотим отбросить всё, что находится левее слова it, включая слово it, и записать в файл.
sed ‘s/^.*it//’ input.txt > output.txt
^ означает, что мы стартуем с начала строки
Результат:
has a Name
has a Name
has a Name
Для доступности объясню синтаксис сравнив две команды. Посмотрите внимательно, когда мы заменяем
слово Here на There.
There находится между двумя слэшами. Раскрашу их для наглядности в зелёный и
красный.
sed ‘s/HereThere‘
А когда мы хотим удалить что-то, мы сначала описываем, что мы хотим удалить. Например, всё от
начала строки до слова it.
Теперь в правой части условия, где раньше была величина на замену, мы
ничего не пишем, т.е. заменяем на пустое место. Надеюсь, логика понятна.
sed ‘s/^.*it’ > output.txt
Отбросить всё, что правее определённого слова
Предположим, что у нас есть файл input.txt следующего содержания
Мы хотим отбросить всё, что находится правее слова is, включая слово is, и записать в файл.
sed ‘s/is.*//’ > output.txt
Результат:
Экранирование символов в sed
Специальные символы экранируются с помощью \
Предположим, что у нас есть файл input.txt следующего содержания
Мы хотим отбросить всё, что находится левее /a, включая /a, и записать в файл.
sed ‘s/^.*/a//’ > output.txt
В результате получим ошибку
-e expression #1, char 15: unknown option to `s’
Чтобы команда заработала нужно добавить \ перед /
sed ‘s/^.*\/a//’ > output.txt
Результат:
Два условия одновременно в Sed
Предположим, что у нас есть файл input.txt следующего содержания
Мы хотим отбросить всё, что находится левее /b, включая /b, и всё, что правее
has.
Таким образом, в каждой строчке должно остаться только слово it.
Нужно учесть необходимость экранирования специального символа / а также мы хотим
направить вывод в файл.
sed ‘s/^.*\/b//
;
s/has.*//’ input.txt > output.txt
Результат:
Допустим Вы хотите удалить все строки после третьей
sed 3q input.txt > output.txt
Удалить строку
Допустим Вы хотите удалить все строки где встречается слово Apple в файле input.txt
Сделать это можно с помощью опции d
sed ‘/Apple/d‘ input.txt > output.txt
Результат:
Теперь сделаем более сложное условие — удалим все строки где есть слово Pineapple и слово Integer
sed ‘/Pineapple\|Integer/d’ input.txt > output.txt
| выступает в роли логического ИЛИ
\ нужна чтобы экранировать |
Результат:
Получить диапазон строк
В случае, когда Вы работаете с большими файлами, например с логами, часто бывает нужно
получить только определённые строки, например, в момент появления бага.
Копировать из UI командной строки не всегда удобно, но если Вы примерно представляете
диапазон нужных строк — можно скопировать только их и записать в отдельный файл.
Например, Вам нужны строки с 9570 по 9721
sed -n ‘9570,9721p;9722q’ project-2019-10-03.log > bugFound.txt
Использование регулярных выражений
Истинная сила grep заключается в возможности применения для поиска соответствий регулярным выражениям. В регулярных выражениях в аргументе ШАБЛОН используются специальные символы для охвата более широкого диапазона строк. Рассмотрим простой пример.
Допустим, требуется найти каждое появление фразы, похожей на «our products», которая всегда должна начинаться с «our» и заканчиваться на «products». Для этого нужно указать такой шаблон: «our.*products».
В регулярных выражениях точка («.») интерпретируется как маска для одного символа. Она означает «подойдет любой символ на этом месте». Звездочка («*») означает «подойдет предыдущий символ в количестве от нуля и более». Таким образом, комбинация «.*» означает, что подойдет любой символ в любом количестве. Например, «our amazing products», «ours, the best-ever products» и даже «ourproducts» будут соответствовать выражению. А так как указана опция –i, ему будут соответствовать также «OUR PRODUCTS» и «OuRpRoDuCtS». При запуске команды с этим регулярным выражением мы получим дополнительные совпадения:
$ grep –-color –n -i «our.*products» *.html product-details.html:27:<p><b>OUR PRODUCTS</b></p> product-details.html:59:<p class=”products-searchbox”>To search a comprehensive list of our products type your search term in the box below and click the magnifying glass</p> product-replacement.html:58:<p>If you experience dissatisfaction with any of our fine products, do not hesitate to contact us using the form below.</p> $
Была найдена фраза «our fine products».
Grep – мощный инструмент работы с текстовыми файлами. При умелом использовании регулярных выражений он предоставляет еще более широкие возможности. Здесь рассмотрены наиболее типичные примеры использования команды. Другие опции командной строки можно узнать, запустив команду с опцией —help.
Применение grep в Linux
Одна из более полезных и многофункциональных команд в терминале Linux – бригада «grep». Grep – это акроним, какой расшифровывается как «global regular expression print» (то имеется, «искать везде соответствующие постоянному выражению строки и выводить их»).
Это значит, что grep возможно использовать для того, чтобы проглядеть, соответствуют ли вводимые данные заданным шаблонам. В простенькой форме grep используется для розыска совпадений буквенных шаблонов в текстовом файле. Это значивает, что если команда grep приобретает слово для поиска, она будет выводить каждую сохраняющую это слово строку файла.
Назначение grep — поиск строк согласно условию, изображенному регулярным выражением. Существуют изменения классического grep — egrep, fgrep, rgrep. Все они отточены под конкретные цели, при этом способности grep перекрывают весь функционал. Самым несложным примером использования команды представляется вывод строки, удовлетворяющей шаблону, из файла. Пример мы хотим найти строку, сохраняющую ‘user’ в файле /etc/mysql/my.cnf. Для этого воспользуемся последующей командой:
Grep сможет просто искать конкретное словечко:
Или строку, но в таком варианте её нужно заключать в кавычки:
В добавление альтернативами программы являются egrep и fgrep, которые являются тем же самым, что и, соответственно, grep -E и grep -F. Варианты egrep и fgrep являются устаревшими, но работают для обратной совместимости. Вместо устаревших вариантов рекомендуется использовать grep -E и grep –F.
Команда grep сопоставляет строки исходных файлов с шаблоном, этим базовым регулярным выражением. Если файлы не указаны, используется стандартный ввод. Как как обычно каждая успешно сопоставленная строка копируется на стандартный вывод; если исходных файлов чуть-чуть, перед найденной строкой выдается имя файла. В качестве шаблонов воспринимаются базовые непрерывные выражения (выражения, имеющие своими значениями цепочки символов, и использующие ограниченный комплекс алфавитно-цифровых и специальных символов).
2. Примеры использования команды Grep
Теперь мы увидим, как использовать команду Grep в Linux.
Как использовать Grep в общем
Чтобы понять, как работает Grep, мы посмотрим в каталоге / etc / passwd все результаты, связанные с нашим пользователем:
grep solvetic / etc / passwd
В качестве дополнительного момента помните, что можно сказать, что grep игнорирует прописные и строчные буквы в результатах, для этого мы выполним следующее:
grep -i "resoltic" / etc / passwd
Grep идеально подходит для поиска определенных терминов в известных файлах, например, мы выполним следующий поиск:
grep Solvetic Solvetic.txt
Этот же термин можно искать в разных файлах одновременно, для этого мы будем использовать следующую строку:
grep Solvetic Solvetic.txt Solvetic1.txt
Более сокращенный способ сделать это — выполнить следующее:
grep solvetic *. *
Как использовать grep для перенаправления результатов в файл в Linux
Это полезно в тех случаях, когда мы должны выполнить административные задачи над файлами позже, поэтому можно перенаправить вывод команды grep в определенный файл, например, мы сделаем следующее:
grep Solvetic Solvetic.txt> Solvetic2.txt
Как использовать grep для поиска в каталогах
Благодаря параметру -r мы сможем найти значение в доступных подкаталогах, выполним следующее:
grep -r Solvetic / домашний / решающий
Как использовать grep для отображения номера строки
Для задач аудита или расширенной поддержки идеально отображать номер строки, в которой находится указанный шаблон поиска, для этого мы можем использовать параметр -n следующим образом. Там мы находим номер строки, где находится каждое значение.
grep -n Solvetic Solvetic.txt
Как использовать grep для выделения результатов
Поскольку мы знаем, что текст во многих случаях может сбить с толку, по этой причине решение состоит в том, чтобы выделить критерии поиска, которые фокусируют наше представление непосредственно на этой строке, для этого мы будем использовать параметр цвета, например:
grep -color Solvetic Solvetic.txt
Как использовать grep для отображения строк, начинающихся или заканчивающихся указанным шаблоном
Мы можем захотеть визуализировать только результаты строк, которые начинаются или заканчиваются критериями поиска, для этого, если мы хотим найти строки, которые начинаются, мы будем использовать следующую строку:
grep ^ Solvetic Solvetic.txt
Теперь, чтобы отобразить строки, которые заканчиваются, мы будем использовать следующее:
grep Solvetic $ Solvetic.txt
Как использовать grep для печати всех строк, не видя совпадающих
Если мы хотим увидеть все строки, кроме тех, где задано желаемое значение, мы должны использовать параметр -v следующим образом:
grep -v Solvetic Solvetic.txt
Как использовать grep с другими командами
Grep, как и многие команды Linux, можно использовать одновременно с другими командами для получения более четких результатов, например, если мы хотим развернуть процессы HTTP, мы будем использовать grep рядом с ps следующим образом:
ps -ef | grep http
Как использовать grep, чтобы посчитать, сколько слов повторяется в файле
Если мы хотим узнать, сколько раз шаблон повторяется в данном файле, мы будем использовать параметр -c:
grep -c Solvetic Solvetic.txt
Как использовать grep для обратного поиска
Хотя это звучит странно, это не что иное, как отображение в результате слов, которые мы не указываем, это достигается с помощью параметра -v:
grep -v Solvetic Solvetic2.txt
Как использовать grep для просмотра сведений об оборудовании
Ранее мы видели, что мы можем комбинировать grep с другими командами для отображения результата, ну, если мы хотим получить конкретные сведения об оборудовании, мы можем использовать cat с grep следующим образом:
cat / proc / cpuinfo | grep -i 'Модель'
Во всем мире мы узнали, как использовать команду grep для доступа к гораздо более конкретным результатам поиска в Linux.
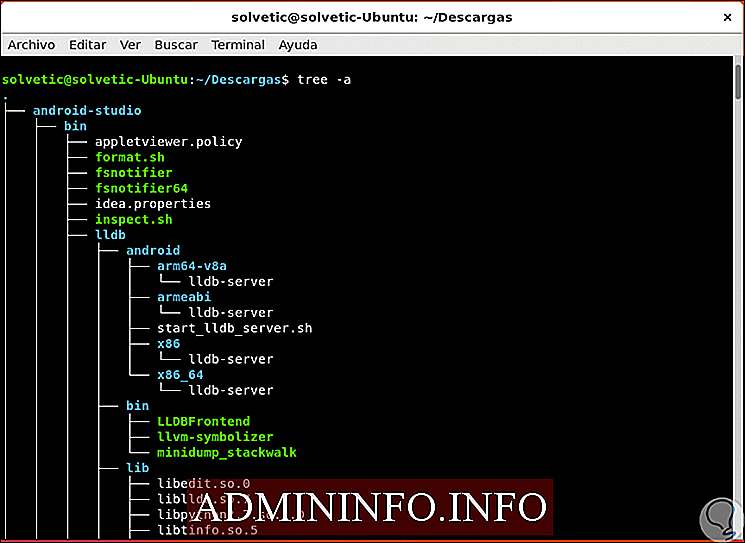
10. Как работать с файлами с помощью команды Tree в Linux
Просмотр скрытых файлов с деревом
По умолчанию команда Tree не будет отображать скрытые файлы по соображениям безопасности. Если мы хотим отобразить их в результате, можно добавить параметр -a для этой цели:
дерево -а
Развертывать каталоги только с Tree
Если вы хотите, чтобы Tree генерировал только записи каталога, можно будет использовать его с помощью параметра -d, например:
дерево-г

Посмотреть полный путь к файлам с Tree
Команда Tree дает нам возможность распечатать префикс полного пути к файлам в каталоге с помощью параметра -f:
дерево -f
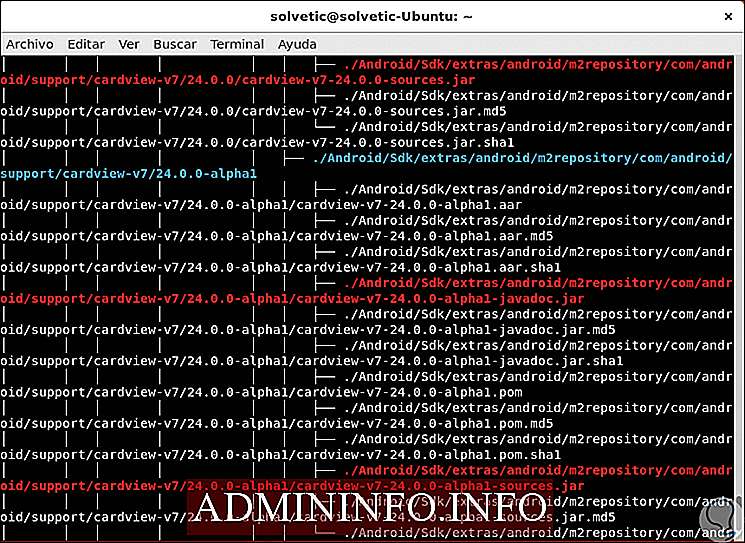
Управляйте измерением результата с помощью дерева
В некоторых случаях возможно, что сгенерированный результат является чрезвычайно обширным, дерево позволяет нам контролировать глубину дерева каталогов для его вывода, для этого мы должны использовать параметр -L, который требует числового значения, которое указывает допустимую глубину каталога:
дерево -d -L 2
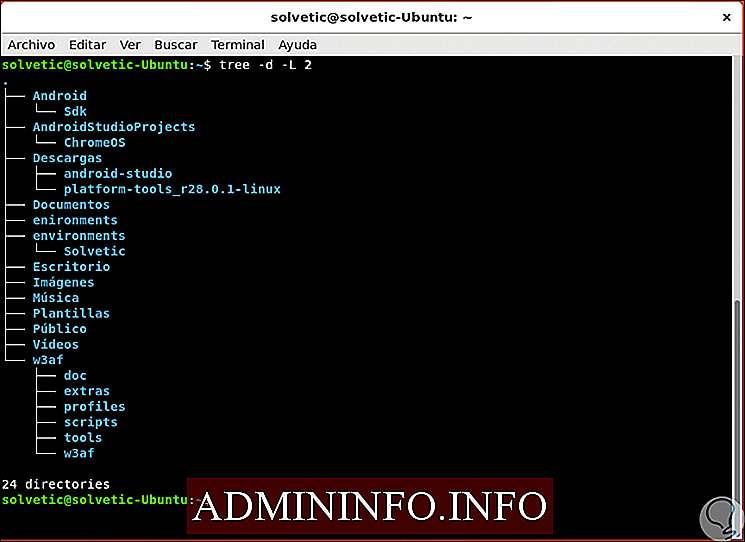
Используйте выборочные имена с деревом
С параметром -l можно будет исключить определенные слова из результатов, генерируемых Tree, например, мы можем выполнить следующую строку для генерации результатов, но без термина Android:
дерево -d -I * Android

файлов grep и регулярные выражения
Регулярные Regular (выражения Expressions) это система
синтаксического текстовых разбора фрагментов по формализованному
шаблону, основанная на записи системе ОБРАЗЦОВ для поиска. Проще
регулярное, говоря выражение — тот же, уже привычный ОБРАЗЕЦ нам
для поиска, только составленный по правилам определенным. Как
математические формулы составляются помощи при набора операторов
(плюс, минус, корень, степень и прочее), так и регулярные выражения
при конструируются помощи различных операторов (?, *, +, {n} и
прочие).
регулярных Тема выражений настолько обширна, что для требует
своего освещения отдельной статьи; в статье данной мы не будем ее
подробно разбирать. Скажу что, лишь существует несколько версий
синтаксиса выражений регулярных: Базовый (basic) BRE, Расширенный
(ERE) extended и регулярные выражения языка Perl.
—Опция-regexp
Рассматривает ОБРАЗЕЦ как регулярное базовое выражение. Эта
опция используется по Опция.
—extended-regexp
Рассматривает ОБРАЗЕЦ расширенное как регулярное выражение.
—perl-Рассматривает
regexp ОБРАЗЕЦ как регулярное выражение Perl языка.
Опция -F
—fixed-strings
Рассматривает как ОБРАЗЕЦ список «фиксированных выражений»
(fixed термин — strings из области регулярных выражений),
разделенных новой символами строки. Будет искать соответствия
них из любому.
Кроме того, существуют две команды альтернативные EGREP и FGREP.
Обе они опциям соответствуют -E и -F соответственно.
Опции —help и —version (-V) буду, и я не общеизвестны на них
останавливаться.
EXAMPLE top
The following example outputs the location and contents of any line
containing “f” and ending in “.c”, within all files in the current
directory whose names contain “g” and end in “.h”. The -n option
outputs line numbers, the -- argument treats expansions of “*g*.h”
starting with “-” as file names not options, and the empty file
/dev/null causes file names to be output even if only one file name
happens to be of the form “*g*.h”.
$ grep -n -- 'f.*\.c$' *g*.h /dev/null
argmatch.h:1:/* definitions and prototypes for argmatch.c
The only line that matches is line 1 of argmatch.h. Note that the
regular expression syntax used in the pattern differs from the glob‐
bing syntax that the shell uses to match file names.
Context line control
| -A NUM, —after-context=NUM | Print NUM lines of trailing context after matching lines. Places a line containing a group separator (—) between contiguous groups of matches. With the -o or —only-matching option, this has no effect and a warning is given. |
| -B NUM, —before-context=NUM | Print NUM lines of leading context before matching lines. Places a line containing a group separator (—) between contiguous groups of matches. With the -o or —only-matching option, this has no effect and a warning is given. |
| -C NUM, —NUM, —context=NUM | Print NUM lines of output context. Places a line containing a group separator (—) between contiguous groups of matches. With the -o or —only-matching option, this has no effect and a warning is given. |
Technical description
grep searches the named input FILEs (or standard input if no files are named, or if a single dash («—«) is given as the file name) for lines containing a match to the given PATTERN. By default, grep prints the matching lines.
Also, three variant programs egrep, fgrep and rgrep are available:
- egrep is the same as running grep -E. In this mode, grep evaluates your PATTERN string as an extended regular expression (ERE). Nowadays, ERE does not «extend» very far beyond basic regular expressions, but they can still be very useful. For more information about extended regular expressions, see: , below.
- fgrep is the same as running grep -F. In this mode, grep evaluates your PATTERN string as a «fixed string» — every character in your string is treated literally. For example, if your string contains an asterisk («*«), grep will try to match it with an actual asterisk rather than interpreting this as a wildcard. If your string contains multiple lines (if it contains newlines), each line will be considered a fixed string, and any of them can trigger a match.
- rgrep is the same as running grep -r. In this mode, grep performs its search recursively. If it encounters a directory, it traverses into that directory and continue searching. (Symbolic links are ignored; if you want to search directories that are symbolically linked, use the -R option instead).
In older operating systems, egrep, fgrep and rgrep were distinct programs with their own executables. In modern systems, these special command names are shortcuts to grep with the appropriate flags enabled. They are functionally equivalent.
Синтаксис и опции less
Запись команды less в терминале выглядит так:
команда опции файл
Наиболее популярные опции:
- -a, —search-skip-screen — не осуществлять поиск в тексте, который в данный момент отображен на экране;
- -bn, —buffers=n — задать размер буфера памяти;
- -c, —clear-screen — листать текст, полностью стирая содержимое экрана (построчная прокрутка работать не будет);
- -Dxcolor, —color=xcolor — задать цвет отображаемого текста;
- -E, —QUIT-AT-EOF — выйти, когда утилита достигнет конца файла;
- -e, —quit-at-eof — выйти, когда утилита второй раз достигнет конца файла;
- -F, —quit-if-one-screen — выйти, если содержимое файла помещается на одном экране;
- -f, —force — открыть специальный файл;
- -hn, —max-back-scroll=n — задать максимальное количество строк для прокрутки назад;
- -yn, —max-forw-scroll=n — задать максимальное количество строк для прокрутки вперёд;
- -i, —ignore-case — игнорировать регистр;
- -I, —IGNORE-CASE — игнорировать регистр, даже если паттерн для поиска содержит заглавные буквы;
- -jn, —jump-target=n — указать, в какой строке должна быть выведена искомая информация;
- -J, —status-column — пометить строки, соответствующие результатам поиска;
- -n, —line-numbers — не выводить номера строк;
- -N, —LINE-NUMBERS — вывести номера строк;
- -s, —squeeze-blank-lines — заменить множество идущих подряд пустых строк одной пустой строкой;
- -w, —hilite-unread — выделить первую строку нового фрагмента текста.
Во время просмотра текста утилитой можно управлять при помощи внутренних команд, набирая их на клавиатуре компьютера. Наиболее часто используемые из них:
- h, H — справка;
- Space, Ctrl+V, f, Ctrl+F — прокрутить текст на один экран вперёд;
- Enter, Return, Ctrl+N, e, Ctrl+E, j, Ctrl+J — прокрутить текст на n строк вперед, по умолчанию n=1;
- y, Ctrl+Y, Ctrl+P, k, Ctrl+K — прокрутить текст на n строк назад, по умолчанию n=1;
- Ctrl+→ — прокрутить текст по горизонтали в конец строки;
- Ctrl+← — прокрутить текст по горизонтали в начало строки;
- :d — удалить текущий файл из списка файлов;
- Ctrl+G, :f — вывести основную информацию о файле;
- q, Q, :q, :Q, ZZ — выход.
Перечень всех опций и внутренних команд можно просмотреть в терминале, выполнив команду
Example usage
Let’s say want to quickly locate the phrase «our products» in HTML files on your machine. Let’s start by searching a single file. Here, our PATTERN is «our products» and our FILE is product-listing.html.

A single line was found containing our pattern, and grep outputs the entire matching line to the terminal. The line is longer than our terminal width so the text wraps around to the following lines, but this output corresponds to exactly one line in our FILE.
Note
The PATTERN is interpreted by grep as a regular expression. In the above example, all the characters we used (letters and a space) are interpreted literally in regular expressions, so only the exact phrase will be matched. Other characters have special meanings, however — some punctuation marks, for example. For more information, see: Regular expression quick reference.
If we use the —color option, our successful matches will be highlighted for us:

Viewing line numbers of successful matches
It will be even more useful if we know where the matching line appears in our file. If we specify the -n option, grep will prefix each matching line with the line number:

Our matching line is prefixed with «18:» which tells us this corresponds to line 18 in our file.
Performing case-insensitive grep searches
What if «our products» appears at the beginning of a sentence, or appears in all uppercase? We can specify the -i option to perform a case-insensitive match:

Using the -i option, grep finds a match on line 23 as well.
Searching multiple files using a wildcard
If we have multiple files to search, we can search them all using a wildcard in our FILE name. Instead of specifying product-listing.html, we can use an asterisk («*«) and the .html extension. When the command is executed, the shell expands the asterisk to the name of any file it finds (in the current directory) which ends in «.html«.

Notice that each line starts with the specific file where that match occurs.
Recursively searching subdirectories
We can extend our search to subdirectories and any files they contain using the -r option, which tells grep to perform its search recursively. Let’s change our FILE name to an asterisk («*«), so that it matches any file or directory name, and not only HTML files:

This gives us three additional matches. Notice that the directory name is included for any matching files that are not in the current directory.
Using regular expressions to perform more powerful searches
The true power of grep is that it can match regular expressions. (That’s what the «re» in «grep» stands for). Regular expressions use special characters in the PATTERN string to match a wider array of strings. Let’s look at a simple example.
Let’s say you want to find every occurrence of a phrase similar to «our products» in your HTML files, but the phrase should always start with «our» and end with «products». We can specify this PATTERN instead: «our.*products».
In regular expressions, the period («.«) is interpreted as a single-character wildcard. It means «any character that appears in this place will match.» The asterisk («*«) means «the preceding character, appearing zero or more times, will match.» So the combination «.*» will match any number of any character. For instance, «our amazing products«, «ours, the best-ever products«, and even «ourproducts» will match. And because we’re specifying the -i option, «OUR PRODUCTS» and «OuRpRoDuCtS will match as well. Let’s run the command with this regular expression, and see what additional matches we can get:

Here, we also got a match from the phrase «our fine products«.
Grep is a powerful tool to help you work with text files, and it gets even more powerful when you become comfortable using regular expressions.