Простые sql запросы
Содержание:
- Тинькофф Инвестиции от Тинькофф Брокер. Достоинства
- Операции записи
- Какие типы СУБД в соответствии с моделями данных вы знаете?
- Что такое язык запросов SQL?
- Установка
- Работа с таблицами.
- Самостоятельная работа для закрепления материала
- DML и записи
- Команды языка определения данных
- Общая характеристика языка запросов SQL
- Соединения (джойны)
- 5. Агрегирование
- 6. Подзапросы
- Команда DESCRIBE
- Назовите четыре основных типа соединения в SQL
- SQL Учебник
- Запрос обновления данных (update)
- Команды языка управления транзакциями
- Типы данных и выражения sql
- Вывод статистики с накоплением по дате
Тинькофф Инвестиции от Тинькофф Брокер. Достоинства
Операции записи
Большинство операций записи в базе данных довольно просты, если сравнивать с более сложными операциями чтения.
7.1 Update
Синтаксис запроса семантически совпадает с запросом на чтение. Единственное отличие в том, что вместо выбора колонок ‘ом, мы задаем знаения ‘ом.
Если все книги Дэна Брауна потерялись, то нужно обнулить значение количества. Запрос для этого будет таким:
делает то же самое, что раньше: выбирает строки. Вместо , который использовался при чтении, мы теперь используем . Однако, теперь нужно указать не только имя колонки, но и новое значение для этой колонки в выбранных строках.
7.2 Delete
Запрос это просто запрос или без названий колонок. Серьезно. Как и в случае с и , блок остается таким же: он выбирает строки, которые нужно удалить. Операция удаления уничтожает всю строку, так что не имеет смысла указывать отдельные колонки. Так что, если мы решим не обнулять количество книг Дэна Брауна, а вообще удалить все записи, то можно сделать такой запрос:
7.3 Insert
Пожалуй, единственное, что отличается от других типов запросов, это . Формат такой:
Где , , это названия колонок, а , и это значения, которые нужно вставить в эти колонки, в том же порядке. Вот, в принципе, и все.
Взглянем на конкретный пример. Вот запрос с , который заполняет всю таблицу «books»:
Какие типы СУБД в соответствии с моделями данных вы знаете?
Этот вопрос по SQL предполагает не просто назвать, но и дать краткое описание каждому типу.
Существует несколько типов СУБД:
- Реляционные, которые поддерживают установку связей между таблицами с помощью первичных и внешних ключей. Пример — MySQL.
- Flat File — базы данных с двумерными файлами, в которых содержатся записи одного типа и отсутствует связь с другими файлами, как в реляционных. Пример — Excel.
- Иерархические подразумевают наличие записей, связанных друг с другом по принципу отношений один-к-одному или один-ко-многим. А вот для отношений многие-ко-многим следует использовать реляционную модель. Пример — Adabas.
- Сетевые похожи на иерархические, но в этом случае «ребёнок» может иметь несколько «родителей» и наоборот. Примеры — IDS и IDMS.
- Объектно-ориентированные СУБД работают с базами данных, которые состоят из объектов, используемых в ООП. Объекты группируются в классы и называются экземплярами, а классы в свою очередь взаимодействуют через методы. Пример — Versant.
- Объектно-реляционные обладают преимуществами реляционной и объектно-ориентированной моделей. Пример — IBM Db2.
- Многомерная модель является разновидностью реляционной и использует многомерные структуры. Часто представляется в виде кубов данных. Пример — Oracle Essbase.
- Гибридные состоят из двух и более типов баз данных. Используются в том случае, если одного типа недостаточно для обработки всех запросов. Пример — Altibase HDВ.
3
Что такое язык запросов SQL?
Язык запросов sql используется программистами наиболее широко. Причиной тому является повсеместное распространение динамических веб сайтов. Как правило, такие ресурсы имеют гибкую оболочку. Но основной костяк такого сайта составляют базы данных. Если вы начинающий программист, вы просто обязаны освоить структурированный язык запросов SQL.
Зачем нужно знать язык запросов SQL?
Освоив язык запросов sql, вы с легкостью сможете писать приложения для WordPress. Это один из самых популярных блоговых движков в мире. Вы сможете писать sql запросы любой сложности, ведь писать sql запросы — это основное при изучении sql. На сайте запросы sql примеры найти не сложно, sql примеры Вы найдете в разделе SQL SELECT (запросы sql примеры).
Недавно появившийся веб ресурс sql-language.ru содержит массу информации касающейся языка запроса sql. По сути дела данный веб-сайт составляет огромный sql справочник. На сайте грамотно и в доступной форме рассмотрены запросы в sql.
Ресурс имеет раздел язык запросов sql для начинающих. Здесь вы можете получить начальные сведения о языке. Приведены основные возможности, которые будут доступны программистам на sql. В общих чертах это хранение и получение данных, их обработка и система команд. В данном разделе приведены типы команд, которые включает язык запросов sql и рассмотрено их назначение. Раздел описывающий данные входящие в язык запросов sql описывает строковые, числовые и прочие типы данных. На каждый тип приведено подробное описание и определена допустимая величина строки. Структурированный язык запросов sql предполагает аккуратное использование типов данных. Также в данном разделе содержится подробная информация по типам совместимым с Access и Oracle. Раздел привилегий языка запроса sql, расписывает как распределить или частично ограничить доступ к данным. Особенно это востребовано для веб сайтов с динамичным содержимым. Примером таких сайтов являются форумы или корпоративные сайты. Возможность редактирования отдельных данных допускается не для всех. Вот здесь то и пригодятся привилегии, которые допускает язык запросов sql. Вы сможете создать систему паролей и отсечь часть пользователей от активных действий. Раздел индексы, языка запроса sql, объясняет, как добиться максимальной производительности системы. Использование индексации позволит серверу легко и быстро находить данные. Структурированный язык запросов sql фактически создавался для этой цели. Простота и удобство в поиске данных, послужило быстрому признанию и распространению языка запроса sql. В восьмидесятых годах язык был признан стандартом для работы с базами данных. С тех пор язык запросов sql используется на большинстве серверов.
Еще один наиболее масштабный раздел сайта это команды. Пожалуй этот сектор рассмотрен на сайте sql-language.ru наиболее подробно. Как обычно, для начинающих приведена общая описательная часть о типах команд языка запроса sql. Рассмотрены такие общие типы как команды определения данных, команды языка управления, управление транзакциями и манипулирование данными. В дальнейшем, каждая из команд рассмотрена в деталях. Детально описан синтаксис команды, назначение, и конечный результат ее действия. Еще один серьезный раздел сайта посвящен условиям языка запроса sql. Здесь подробно описано как организовать обработку данных определенным образом. Возможны гибкие варианты, ограничения или исключения данных из процесса обработки.
Вся информация на сайте является абсолютно бесплатной. Сайт обладает достаточно простой навигацией. В структуре данных довольно легко ориентироваться даже неподготовленному человеку. Для новичков впервые осваивающих язык запросов sql веб сайт будет хорошим подспорьем. Оставьте закладку на sql-language.ru и вы всегда сможете найти необходимую информацию, касающуюся языка запроса sql. Для тех, кто уже сталкивался с программированием с использованием языка запроса sql, ресурс не будет лишним. Наверняка не всякий держит все тонкости языка в голове. Периодически возникают вопросы, требующие припоминания основ и деталей. Для зарегистрированных пользователей, на сайте предусмотрена возможность оставлять комментарии. Вы сможете задать вопрос, и прочитать, что по этому поводу думают другие. Удачи вам на поприще программирования.
Установка
Если для своей работы вы используете программную среду OpenServer, то этот раздел можно смело пропустить, так как в состав OpenServer уже входит свежая версия MySQL.
Последняя версия MySQL доступна для загрузке по ссылке: https://dev.mysql.com/downloads/mysql/
На этой странице следует выбрать «MySQL Installer for Windows» и нажать на кнопку «Download» для загрузки.
В процессе установки запомните директорию, куда вы устанавливаете MySQL (скрывается под ссылкой «Advanced options»).
На шаге «Accounts and Roles» установщик потребует придумать пароль для доступа к БД (MySQL Root Password) — обязательно запомните или запишите этот пароль — он вам ещё понадобится.
Работа с таблицами.
Создадим таблицу со столбцами id, user, pass, data. Причем id будет автоматически увеличивать свое значение :
- INT : тип столбца среднее целое число. Подписанный диапазон составляет от -2147483648 до 2147483647 .
- VARCHAR : тип строка переменной длины ,может содержать буквы, цифры и специальные символы(100 , максимально сто символов).
- NOT NULL : столбец не может не содержать значение ( не может быть пустым).
- AUTO_INCREMENT : создает уникальный идентификатор при вставке новой записи в таблицу.
- PRIMARY KEY ( id ) : данное ограничение позволяет однозначно идентифицировать каждую запись в таблице. Первичный ключ должен содержать уникальные значения. Первичный ключ не может содержать NULL значений. Каждая таблица должна иметь первичный ключ, и каждая таблица может иметь только один первичный ключ.
- DATA : тип дата. Формат: гггг-ММ-ДД.
Просмотр таблиц в базе :
Просмотра сведений о таблице :
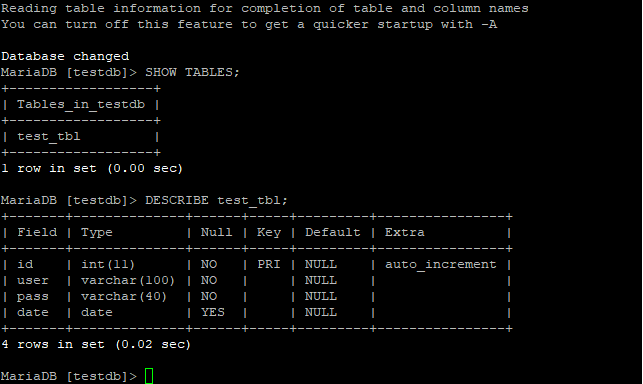
Добавление данных в таблицу :
Если заполняем все столбцы, можно просто перечислить значения :
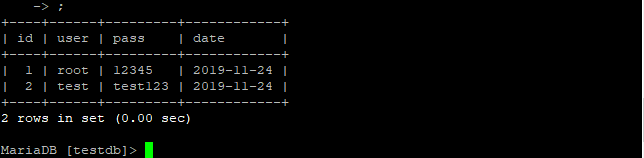
Обновление данных в таблице. Скажем заменим поля user и pass для id 1 :
WHERE это условие при котором будет произведена замена.
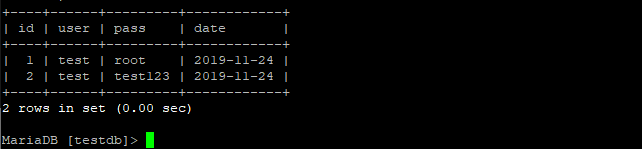
Удаление всех данных из таблице :
Удаление таблицы :
Самостоятельная работа для закрепления материала
| LCode | LDescr |
|---|---|
| 1 | L-1 |
| 2 | L-2a |
| 2 | L-2b |
| 3 | L-3 |
| 5 | L-5 |
| RCode | RDescr |
|---|---|
| 2 | B-2a |
| 2 | B-2b |
| 3 | B-3 |
| 4 | B-4 |
| LCode | LDescr | RCode | RDescr |
|---|---|---|---|
| 2 | L-2a | 2 | B-2a |
| 2 | L-2a | 2 | B-2b |
| 2 | L-2b | 2 | B-2a |
| 2 | L-2b | 2 | B-2b |
| 3 | L-3 | 3 | B-3 |
| LCode | LDescr | RCode | RDescr |
|---|---|---|---|
| 1 | L-1 | NULL | NULL |
| 2 | L-2a | 2 | B-2a |
| 2 | L-2a | 2 | B-2b |
| 2 | L-2b | 2 | B-2a |
| 2 | L-2b | 2 | B-2b |
| 3 | L-3 | 3 | B-3 |
| 5 | L-5 | NULL | NULL |
| LCode | LDescr | RCode | RDescr |
|---|---|---|---|
| 2 | L-2a | 2 | B-2a |
| 2 | L-2b | 2 | B-2a |
| 2 | L-2a | 2 | B-2b |
| 2 | L-2b | 2 | B-2b |
| 3 | L-3 | 3 | B-3 |
| NULL | NULL | 4 | B-4 |
| LCode | LDescr | RCode | RDescr |
|---|---|---|---|
| 1 | L-1 | NULL | NULL |
| 2 | L-2a | 2 | B-2a |
| 2 | L-2a | 2 | B-2b |
| 2 | L-2b | 2 | B-2a |
| 2 | L-2b | 2 | B-2b |
| 3 | L-3 | 3 | B-3 |
| 5 | L-5 | NULL | NULL |
| NULL | NULL | 4 | B-4 |
| LCode | LDescr | RCode | RDescr |
|---|---|---|---|
| 1 | L-1 | 2 | B-2a |
| 2 | L-2a | 2 | B-2a |
| 2 | L-2b | 2 | B-2a |
| 3 | L-3 | 2 | B-2a |
| 5 | L-5 | 2 | B-2a |
| 1 | L-1 | 2 | B-2b |
| 2 | L-2a | 2 | B-2b |
| 2 | L-2b | 2 | B-2b |
| 3 | L-3 | 2 | B-2b |
| 5 | L-5 | 2 | B-2b |
| 1 | L-1 | 3 | B-3 |
| 2 | L-2a | 3 | B-3 |
| 2 | L-2b | 3 | B-3 |
| 3 | L-3 | 3 | B-3 |
| 5 | L-5 | 3 | B-3 |
| 1 | L-1 | 4 | B-4 |
| 2 | L-2a | 4 | B-4 |
| 2 | L-2b | 4 | B-4 |
| 3 | L-3 | 4 | B-4 |
| 5 | L-5 | 4 | B-4 |
DML и записи
В командах INSERT и DELETE можно использовать записи PL/SQL. Пример:
Это важное нововведение облегчает работу программиста по сравнению с работой на уровне отдельных переменных или полей записи. Во-первых, код становится более компактным — с уровня отдельных значений вы поднимаетесь на уровень записей
Нет
необходимости объявлять отдельные переменные или разбивать запись на поля при передаче данных команде DML. Во-вторых, повышается надежность кода — если вы работаете с записями типа %ROWTYPE и обходитесь без явных манипуляций с полями, то в случае модификации базовых таблиц и представлений вам придется вносить значительные изменения в программный код.
В разделе «Ограничения, касающиеся операций вставки и обновления» приведен список ограничений на использование записей в командах DML. Но сначала мы посмотрим, как использовать DML на основе записей в командах INSERT и UPDATE.
Вставка на основе записей
В командах INSERT записи можно использовать как для добавления единственной строки, так и для пакетной вставки (с использованием команды FORALL). Также возможно создание записей с помощью объявления %ROWTYPE на основе таблицы, в которую производится вставка, или явного объявления командой TYPE на основе типа данных, совместимого со структурой таблицы.
Приведем несколько примеров.
Вставка в таблицу книг данных из записи с объявлением %ROWTYPE
Обратите внимание: имя записи не заключается в скобки. Если мы используем запись вида. Oracle выдаст сообщение об ошибке
Oracle выдаст сообщение об ошибке.
Также можно выполнить вставку данных, взятых из записи, тип которой определен программистом, но этот тип должен быть полностью совместим с определением . Другими словами, нельзя вставить в таблицу запись, содержащую подмножество столбцов таблицы.
Вставка с помощью команды FORALL — этим способом в таблицу вставляются коллекции записей.
Обновление на основе записей
Также существует возможность обновления целой строки таблицы по данным записи PL/SQL. В следующем примере для обновления строки таблицы books используется запись, созданная со спецификацией %ROWTYPE
Обратите внимание на ключевое слово ROW, которое указывает, что вся строка обновляется данными из записи:
Существует несколько ограничений, касающихся обновления строк на основе записей.
- При использовании ключевого слова ROW должна обновляться вся строка. Возможность обновления подмножества столбцов пока отсутствует, но не исключено, что она появится в следующих версиях Oracle. Для любых полей, значения которых остались равными NULL, соответствующему столбцу будет присвоено значение NULL.
- Обновление не может выполняться с использованием вложенного запроса.
Использование записей с условием RETURNING
В команду DML может включаться секция RETURNING, возвращающая значения столбцов (и основанных на них выражений) из обработанных строк. Возвращаемые данные могут помещаться в запись и даже в коллекцию записей:
Заметьте, что в предложении RETURNING перечисляются все столбцы таблицы. К сожалению, Oracle пока не поддерживает синтаксис с символом *.
Ограничения, касающиеся операций вставки и обновления
Если вы захотите освоить операции вставки и обновления с использованием записей, имейте в виду, что на их применение существуют определенные ограничения.
- Переменная типа записи может использоваться либо (1) в правой части секции SET команды UPDATE; (2) в предложении VALUES команды INSERT; (3) в подразделе INTO секции RETURNING.
- Ключевое слово ROW используется только в левой части приложения SET. В этом случае других предложений SET быть не может (то есть нельзя задать предложение SET со строкой, а затем предложение SET с отдельным столбцом).
- При вставке записи не следует задавать значения отдельных столбцов.
- Нельзя указывать в команде INSERT или UPDATE запись, содержащую вложенную запись (или функцию, возвращающую вложенную запись).
- Записи не могут использоваться в динамически выполняемых командах DML (execute immediate). Это потребовало бы от Oracle поддержки динамической привязки типа записи PL/SQL с командой SQL. Oracle же поддерживает динамическую привязку только для типов данных SQL.
Назначение языка SQL и необход… 813 просмотров Ирина Светлова Mon, 28 Oct 2019, 05:40:06
Управление приложениями PL/SQL… 2453 просмотров Rasen Fasenger Thu, 16 Jul 2020, 06:20:48
Встроенные методы коллекций PL… 5342 просмотров sepia Tue, 29 Oct 2019, 09:54:01
Тип данных RAW в PL/SQL 4348 просмотров Doctor Thu, 12 Jul 2018, 08:41:33
Author: Antoni
Другие статьи автора:
Команды языка определения данных
Команды языка определения данных DDL (Data Definition Language, язык определения данных) — это подмножество SQL, используемое для определения и модификации различных структур данных.
К данной группе относятся команды предназначенные для создания, изменения и удаления различных объектов базы данных. Команды CREATE (создание), ALTER (модификация) и DROP (удаление) имеют большинство типов объектов баз данных (таблиц, представлений, процедур, триггеров, табличных областей, пользователей и др.). Т.е. существует множество команд DDL, например, CREATE TABLE, CREATE VIEW, CREATE PROCEDURE, CREATE TRIGGER, CREATE USER, CREATE ROLE и т.д.
Некоторым кажется, что применение DDL является прерогативой администраторов базы данных, а операторы DML должны писать разработчики, но эти два языка не так-то просто разделить. Сложно организовать аффективный доступ к данным и их обработку, не понимая, какие структуры доступны и как они связаны. Также сложно проектировать соответствующие структуры, не зная, как они будут обрабатываться.
Общая характеристика языка запросов SQL
SQL может выполнять операции над таблицами и над данными таблиц.
Язык SQL называют встроенным, т.к. он содержит функций полноценного языка разработки, а ориентируется на доступ к данным, вследствие чего он входит в состав средств разработки приложений. Стандарты языка SQL поддерживают языки программирования Pascal, Fortran, COBOL, С и др.
Существует 2 метода использования встроенного SQL:
- статическое использование языка (статический SQL) – в тексте программы содержатся вызовы функций SQL, которые включают в исполняемый модуль после компиляции.
- динамическое использование языка (динамический SQL) – динамическое построение вызовов функций SQL и их интерпретация. Например, можно обратиться к данным удаленной БД в процессе выполнения программы.
Язык SQL (как и другие языки для работы с БД) предназначен для подготовки и выполнения запросов. В результате выполнения запроса данных из одной или нескольких таблиц получают множество записей, которое называют представлением.
Определение 1
Представление – это таблица, которая формируется в результате выполнения запроса.
Соединения (джойны)
Теперь мы хотим увидеть названия (не обязательно уникальные) всех книг Дэна Брауна, которые были взяты из библиотеки, и когда эти книги нужно вернуть:
Результат:
| Title | Return Date |
|---|---|
| The Lost Symbol | 2016-03-23 00:00:00 |
| Inferno | 2016-04-13 00:00:00 |
| The Lost Symbol | 2016-04-19 00:00:00 |
По большей части запрос похож на предыдущий за исключением секции . Это означает, что мы запрашиваем данные из другой таблицы. Мы не обращаемся ни к таблице “books”, ни к таблице “borrowings”. Вместо этого мы обращаемся к новой таблице, которая создалась соединением этих двух таблиц.
— это, считай, новая таблица, которая была сформирована комбинированием всех записей из таблиц «books» и «borrowings», в которых значения совпадают. Результатом такого слияния будет:
А потом мы делаем запрос к этой таблице так же, как в примере выше. Это значит, что при соединении таблиц нужно заботиться только о том, как провести это соединение. А потом запрос становится таким же понятным, как в случае с «простым запросом» из пункта 3.
Давайте попробуем чуть более сложное соединение с двумя таблицами.
Теперь мы хотим получить имена и фамилии людей, которые взяли из библиотеки книги автора “Dan Brown”.
На этот раз давайте пойдем снизу вверх:
Шаг Step 1 — откуда берем данные? Чтобы получить нужный нам результат, нужно соединить таблицы “member” и “books” с таблицей “borrowings”. Секция JOIN будет выглядеть так:
Шаг 2 — какие данные показываем? Нас интересуют только те данные, где автор книги — “Dan Brown”
Шаг 3 — как показываем данные? Теперь, когда данные получены, нужно просто вывести имя и фамилию тех, кто взял книги:
Супер! Осталось лишь объединить три составные части и сделать нужный нам запрос:
Что даст нам:
| First Name | Last Name |
|---|---|
| Mike | Willis |
| Ellen | Horton |
| Ellen | Horton |
Отлично! Но имена повторяются (они не уникальны). Мы скоро это исправим.
5. Агрегирование
Грубо говоря, агрегирования нужны для конвертации нескольких строк в одну. При этом, во время агрегирования для разных колонок используется разная логика.
Давайте продолжим наш пример, в котором появляются повторяющиеся имена. Видно, что Ellen Horton взяла больше одной книги, но это не самый лучший способ показать эту информацию. Можно сделать другой запрос:
Что даст нам нужный результат:
| First Name | Last Name | Number of books borrowed |
|---|---|---|
| Mike | Willis | 1 |
| Ellen | Horton | 2 |
Почти все агрегации идут вместе с выражением . Эта штука превращает таблицу, которую можно было бы получить запросом, в группы таблиц. Каждая группа соответствует уникальному значению (или группе значений) колонки, которую мы указали в . В нашем примере мы конвертируем результат из прошлого упражнения в группу строк. Мы также проводим агрегирование с , которая конвертирует несколько строк в целое значение (в нашем случае это количество строк). Потом это значение приписывается каждой группе.
Каждая строка в результате представляет собой результат агрегирования каждой группы.
Можно прийти к логическому выводу, что все поля в результате должны быть или указаны в , или по ним должно производиться агрегирование. Потому что все другие поля могут отличаться друг от друга в разных строках, и если выбирать их ‘ом, то непонятно, какие из возможных значений нужно брать.
В примере выше функция обрабатывала все строки (так как мы считали количество строк). Другие функции вроде или обрабатывают только указанные строки. Например, если мы хотим узнать количество книг, написанных каждым автором, то нужен такой запрос:
Результат:
| author | sum |
|---|---|
| Robin Sharma | 4 |
| Dan Brown | 6 |
| John Green | 3 |
| Amish Tripathi | 2 |
Здесь функция обрабатывает только колонку и считает сумму всех значений в каждой группе.
6. Подзапросы
Подзапросы это обычные SQL-запросы, встроенные в более крупные запросы. Они делятся на три вида по типу возвращаемого результата.
Команда DESCRIBE
Команда описывает или выводит список столбцов таблицы вместе с их спецификациями. Кроме того, она позволяет получать описание процедур или пакетов Oracle. Эта команда чрезвычайно полезна при выполнении рутинных обязанностей администратора баз данных. Если, например, нет уверенности в том, какой столбец нужно выбрать в определенной таблице, но точно известно, к какой именно таблице следует выполнить запрос, с помощью команды можно получить список всех столбцов, которые имеются в данной таблице
Поскольку команда может применяться даже в отношении метаданных (словаря данных), с ее помощью можно также очень легко знакомиться с информацией о таблицах и столбцах и их применении, которая является критически важной для работы с базой данных
В листинге ниже показано, как команда позволяет отображать столбцы и типы столбцов таблицы.
SQL> DESCRIBE employees Name Null? Type ---------------------- -------- --------------------- EMPLOYEE_ID NOT NULL NUMBER(6) FIRST_NAME VARCHAR2(20) LAST_NAME NOT NULL VARCHAR2(25) EMAIL NOT NULL VARCHAR2(25) PHONE_NUMBER VARCHAR2(20) HIRE_DATE NOT NULL DATE JOB_ID NOT NULL VARCHAR2(10) SALARY NUMBER(8,2) COMMISSION_PCT NUMBER(2,2) MANAGER_ID NUMBER(6) DEPARTMENT_ID NUMBER(4) SQL>
Назовите четыре основных типа соединения в SQL
Чтобы объединить две таблицы в одну, следует использовать оператор . Соединение таблиц может быть внутренним () или внешним (), причём внешнее соединение может быть левым (), правым () или полным ().
- — получение записей с одинаковыми значениями в обеих таблицах, т.е. получение пересечения таблиц.
- — объединяет записи из обеих таблиц (если условие объединения равно true) и дополняет их всеми записями из обеих таблиц, которые не имеют совпадений. Для записей, которые не имеют совпадений из другой таблицы, недостающее поле будет иметь значение .
- — возвращает все записи, удовлетворяющие условию объединения, плюс все оставшиеся записи из внешней (левой) таблицы, которые не удовлетворяют условию объединения.
- — работает точно так же, как и левое объединение, только в качестве внешней таблицы будет использоваться правая.
Рассмотрим пример соединения SQL таблиц с использованием . Следующий запрос выбирает все заказы с информацией о клиенте:
9
SQL Учебник
SQL ГлавнаяSQL ВведениеSQL СинтаксисSQL SELECTSQL SELECT DISTINCTSQL WHERESQL AND, OR, NOTSQL ORDER BYSQL INSERT INTOSQL Значение NullSQL Инструкция UPDATESQL Инструкция DELETESQL SELECT TOPSQL MIN() и MAX()SQL COUNT(), AVG() и …SQL Оператор LIKESQL ПодстановочныйSQL Оператор INSQL Оператор BETWEENSQL ПсевдонимыSQL JOINSQL JOIN ВнутриSQL JOIN СлеваSQL JOIN СправаSQL JOIN ПолноеSQL JOIN СамSQL Оператор UNIONSQL GROUP BYSQL HAVINGSQL Оператор ExistsSQL Операторы Any, AllSQL SELECT INTOSQL INSERT INTO SELECTSQL Инструкция CASESQL Функции NULLSQL ХранимаяSQL Комментарии
Запрос обновления данных (update)
Запрос обновления данных строится следующим образом:
update table set col1 = val1, col2 = val2, ..., colN = valN where clause;
где update — это начало sql-запроса, table — это конкретное имя таблицы, set — обозначает, что далее будет список требуемых изменений, col1 = val1, col2 = val2, …, colN = valN — это перечисление через запятую колонок с присваиваемыми им значениями, where — указывает, что далее будут перечислены условия отбора, clause — условие фильтра (аналогично delete). Запрос так же заканчивается точкой с запятой.
Примечание: Важно отметить, что часть where с clause являются необязательными. То есть, если фильтр не требуется, то их можно не писать
Однако, если фильтр нужен, то обе составляющих необходимо использовать в запросе.
К примеру, если необходимо не удалить все строки из примера ранее, а указать для всех этих строк дату рождения 31.12.2222 и возраст -203, то sql-запрос выглядел бы так:
update somedata set Age = -203, Date = '31.12.2222' where (Age > 1 and Age < 5) or Name = 'Масяня';
Обратите внимание, что поля Age и Date изменяются только после проверки условий фильтра
Это важно, так как запрос позволяет использовать текущие значения колонок при фильтрации (иначе бы могли возникать несоответствия)
Команды языка управления транзакциями
Команды языка управления транзакциями ( TCL (Тгаnsасtiоn Соntrol Language) ) команды позволяют определить исход транзакции.
Команды управления транзакциями управляют изменениями в базе данных, которые осуществляются командами манипулирования данными.Транзакция (или логическая единица работы) – неделимая с точки зрения воздействия на базу данных последовательность операторов манипулирования данными (чтения, удаления, вставки, модификации) такая, что либо результаты всех операторов, входящих в транзакцию, отображаются в БД, либо воздействие всех этих операторов полностью отсутствует.COMMIT — заканчивает («подтверждает») текущую транзакцию и делает постоянными (сохраняет в базе данных) изменения, осуществленные этой транзакцией. Также стирает точки сохранения этой транзакции и освобождает ее блокировки. Можно также использовать эту команду для того, чтобы вручную подтвердить сомнительную распределенную транзакцию.ROLLBACK — выполняет откат транзакции, т.е. отменяет все изменения, сделанные в текущей транзакции. Можно также использовать эту команду для того, чтобы вручную отменить работу, проделанную сомнительной распределенной транзакцией.
Понятие транзакции имеет непосредственную связь с понятием целостности базы данных. Очень часто база данных может обладать такими ограничениями целостности, которые просто невозможно не нарушить, выполняя только один оператор изменения БД. Например, невозможно принять сотрудника в отдел, название и код которого отсутствует в базе данных.
В системах с развитыми средствами ограничения и контроля целостности каждая транзакция начинается при целостном состоянии базы данных и должна оставить это состояние целостными после своего завершения. Несоблюдение этого условия приводит к тому, что вместо фиксации результатов транзакции происходит ее откат (т.е. вместо оператора COMMIT выполняется оператор ROLLBACK), и база данных остается в таком состоянии, в котором находилась к моменту начала транзакции, т.е. в целостном состоянии.
В связи со свойством сохранения целостности БД транзакции являются подходящими единицами изолированности пользователей, т.е., если с каждым сеансом работы с базой данных ассоциируется транзакция, то каждый пользователь начинает работу с согласованным состоянием базы данных, т.е. с таким состоянием, в котором база данных могла бы находиться, даже если бы пользователь работал с ней в одиночку.
Типы данных и выражения sql
Типы
данных
Символьный
тип данных содержащий буквы, цифры,
специальные символы
CHAR
или CHAR
(n)
– символьные строки фиксированные
данные
VARCHAR
(n)
– символьные строки
Целые
числа
INTЕGER
или INT
– целое для решения которого отводится,
как байта
SMALLINT
– короткое
целое (2 байта)
FLOAT
–
число плавающих точек
DECIMAL
(p)
– аналогично FLOAT
с числовым значение цифр р
DECIMAL
(p,
n)
– аналогично предыдущим, р – общее
количество десятичных чисел
Денежный
тип
MONEY
(p,
n)
– аналогично типу DECIMAL
(p,
n)
Дата
и время
DATE
— дата
TIME
— время
INTERVAL
– временный интервал
DATETIME
– момент время
Двоичные
данные
BINARY
BYTE
BLOB
– хранить данные любого объема в двоичном
коде
Последовательный
тип
SERIAL
– тип данных на основе INTEGER
позволяющий сформировать уникальные
значения
Выражения
Арифметические
выражения
+,
-, *, %, /, ^,
Логические
операции
AND
– логическое умножение
OR
– лог сложение
NOT
–лог отриц
Текстовые
операции
&
— слияние слов
Пример
выражения
Kol*Price
(Kol*Price)/8200
AVG
Язык
SQL
оперирует терминами: таблица, строка,
столбец или колонка.
Полное
имя таблицы: имя _ владельца.имя_таблицы
Полное
имя столбца: имя _ владельца.имя_столбца
Основной
яз SQL составляет операции, условно
разбитые на несколько групп.
Категории
операторов
SQL:
-
Date
Definition Language (DDC) -
Date
Manipulation Language (DML) -
Date
Control Language (DCL) -
Transaction
Control Language (TCL) -
Cursor
Control Language (CCL)
Вывод статистики с накоплением по дате
Предположим, что у нас имеется склад с некими товарами. Товары периодически поступают, и нам бы хотелось видеть в отчете остатки товаров по дням. Поскольку данные о наличии товаров необходимо накапливать, то мы введем пользовательскую переменную. Но есть одно небольшое “но”. Мы не можем использовать в запросе переменные пользователя и группировку данных одновременно (вернее можем, но в итоге получим, не то, что ожидаем), но мы можем использовать вложенный запрос, вместо явно указанной таблицы. Данные в таблице будут предварительно сгруппированы по дате. И уже затем на основе этих данных мы произведем расчет статистики с накоплением.
На первом этапе требуется установить переменную и присвоить ей нулевое значение:
SET @cvalue = 0
В следующем запросе, мы созданную ранее переменную и применим:
SELECT products.Name AS Name, (@cvalue := @cvalue + Orders) as Orders, Date FROM (SELECT ProductID AS ProductID, SUM(Orders) AS Orders, DATE(date) AS Date FROM statistics WHERE ProductID = '1' GROUP BY date) AS statistics JOIN products ON statistics.ProductID = products.id
Итоговый отчет:
+-----------------------+--------+------------+ | Name | Orders | Date | +-----------------------+--------+------------+ | Процессоры Pentium II | 1 | 2014-09-04 | | Процессоры Pentium II | 2 | 2014-09-12 | | Процессоры Pentium II | 4 | 2014-09-14 | | Процессоры Pentium II | 6 | 2014-09-15 | +-----------------------+--------+------------+
Получить используемую в примерах базу данных можно здесь.