«исторический проект»: татарстан первым создаст площадку для общения кластеров
Содержание:
- Что делать, если к вам никто не ходит
- Где открывать
- Как искать резидентов
- Кластер в автомобилестроении и автомобиле — что это такое
- Инструкция
- Что такое кластер в экономике
- Как привлечь инвестиции
- Кластер как метод критического мышления
- Индексы
- Как применять метод кластера на уроках?
- Зоны роста
- Термин
- Существуют ли какие-либо принципы составления «грозди»?
- Внутренняя отметка
- Кластеризация на основе соединений
- Кластеризация на основе плотности
Что делать, если к вам никто не ходит
Реальная проблема, которая может возникнуть, — отсутствие трафика. В небольших городах это связано с недостатком аудитории. Здесь все знают про проект, но у людей нет потребности каждый день приходить в этом место. Значит, надо сделать так, чтобы творческий кластер стал интересен более широкой аудитории. В этом случае я рекомендую не пытаться быть исключительно креативом и подумать в сторону традиционных бизнесов.
Например, арт-завод «Доренберг» расположен не в центре Иркутска, а скорее с края от центра, причём за рекой. Там до сих пор часть территории занимают бизнесы, не имеющие отношения к креативу. Это, например, оптовые магазины, автомастерская и просто офисы. Они не целевые для арт-завода, зато стабильно платят аренду. И этого не надо бояться. На 9000 кв. м в Иркутске просто не хватает креативных бизнесов.
Где открывать
Локация должна быть максимально близка к центру. Обычно креативные кластеры открывают в районах рядом с дорогой недвижимостью. Запускать такой проект на отшибе — плохая идея.
Кластер — это несколько зданий, расположенных на одном земельном участке, желательно не выше четырех-пяти этажей, идеально — два-три. Минимальная общая площадь — 4000 кв. м. Ошибка, которую совершают все начинающие в регионах, — маленькие объекты меньше этой площади. В итоге все деньги, которые они зарабатывают, идут в расходную часть, чистой прибыли нет. Делать маленькие творческие кластеры невыгодно. При большей площади операционные расходы практически не изменятся.
Как искать резидентов
Территория, которая ещё недавно была заброшенной, заживёт своей жизнью в единственном случае — появятся резиденты. Их должно быть не меньше 40. До старта проекта рекомендую найти хотя бы половину арендаторов. И это не кафе, поскольку им нужен трафик, которого в самом начале может и не быть.
Какие это могут быть бизнесы? Любые, у кого есть собственный пул клиентов и кому трафик площадки не нужен (в самом начале его не будет). Например, тату-студии, барбершопы, креативные агентства, антикафе, кулинарные студии и т. д.
Чтобы их найти, изучите креативную индустрию города. Найдите людей из этой тусовки, которые проводят фестивали, открывают антикафе или ивент-площадки. Они всех знают и уже сами задумываются, что неплохо было бы объединиться с партнёрами на одной территории. Из разговора с ними легко понять, чем живёт город.
Кластер в автомобилестроении и автомобиле — что это такое
По поводу кластера в автомобиле необходимо сделать несколько разъяснений. Дело в том, что понятие кластера характерно для отрасли автомобилестроения. Это уже экономика, т.е. кластер здесь – это группа расположенных на одной территории предприятий или организаций, связанных с автомобилестроением.
Например, в России сформировано три таких кластера. Это Приволжский, Центральный и Северо-западный. Они связаны с местом концентрации производств конечной продукции.
В свою очередь, в каждом из этих кластеров можно выделить свои кластерные единицы. Так, для Самарской области, структура автомобильного кластера будет выглядеть следующим образом:
Что же касается непосредственно автомобиля, то здесь также имеется такое понятие как кастер, которое некоторые путают со словом кластер. Связано это с такой технической характеристикой, как развал-схождение.
Здесь понятие кастер – это угол, под которым наклоняется ось поворота колеса по отношению к вертикали. Этот угол является важным параметром подвески автомобиля.
Если кастер небольшой, то сцепление колес с дорогой улучшается. При поездке по неровной дороге в гоночных автомобилях угол кастера уменьшается, а на ровной скоростной трассе – увеличивается.
Если показатель угла продольного смещения колес выходит за заводские стандарты, то это повышает риск поломки в ходовой части и в системе управления.
Однако, если применить к автомобилю стандартное понятие кластера и использовать слово автомобиль в качестве ключевого, то можно составить что-то вроде такой схемы:
Инструкция
Как указано выше, алгоритмы кластеризации можно классифицировать на основе их кластерной модели. В следующем обзоре будут перечислены только наиболее яркие примеры данных инструкций. Поскольку, возможно, существует более 100 опубликованных алгоритмов, не все предоставляют модели для своих кластеров, и поэтому не могут быть легко классифицированы.
Не существует объективно правильного алгоритма кластеризации. Но, как было отмечено выше, инструкция всегда находится в поле зрения наблюдателя. Наиболее подходящий алгоритм кластеризации для конкретной задачи часто приходится выбирать экспериментально, если только нет математической причины для предпочтения одной модели другой. Следует отметить, что алгоритм, разработанный для единственного типа, обычно не работает с набором данных, который содержит радикально другой субъект. Например, k-means не может найти невыпуклые группы.
Что такое кластер в экономике
В экономике понятие кластер включает в себя взаимозаменяемые элементы, относящиеся к самодостаточной локализованной сфере производства или услуг определённого направления.
Это может быть группа взаимосвязанных организаций, компаний, банков, учреждений образования, поставщиков продукции и комплектующих, научно-исследовательских институтов, которые сконцентрированы на некоторой территории, взаимодополняющие друг друга и усиливающие конкурентные преимущества отдельных компаний, а также всего кластера в целом.
Понятие кластера в экономике было предложено в 1990 году американским экономистом М. Портером. Этим термином обозначалась группа конкурентоспособных смежных отраслей хозяйства страны. Причем компании, которые действуют в кластерных отраслях имеют тенденцию к географической концентрации. Поэтому современное определение кластера включает в себя следующее:
По своей сути, они являются не какой-то организацией, а всего на всего, определенной группой, в которую объединяются предприятия одного региона. Эти предприятия являются независимыми и конкурируют с остальными участниками кластера.
Такая форма объединения обладает достаточно высокими показателями конкуренции, кооперации и, само собой эффективностью экономики.
У кластера имеется свой центр, куда входит группа конкурирующих компаний данного кластера. Эта группа выпускает конечный продукт, который реализуется вне кластера.
Кластеры в экономике являются очень важным моментом, поскольку развивая сам кластер, тем самым развивается и экономика региона, повышается качество продукции.
Это связано с усилением конкуренции и более легкого доступа к новым технологиям. Кроме того, увеличивается занятость, повышается качество рабочей силы и, соответственно, повышается конкурентоспособность региона.
Как привлечь инвестиции
В России институциональные инвесторы (банки, инвестиционные фонды) не вкладываются в креативные кластеры, для них это непонятный бизнес. Создание таких проектов у нас всегда чья-то персональная инициатива. Та же «Новая Голландия» появилась только потому, что собственнику Millhouse понравилась идея. Музей стрит-арта — тоже частная инициатива. Инвесторы — всегда знакомые или знакомые знакомых, которые поверили в большую идею и вдохновились ей.
Если инвестор найден, переходим к следующему этапу — планированию и проектированию. На этапе планирования и проектирования для просчёта расходов мы используем доходный метод. Понимая, сколько денег будет приносить творческий кластер в месяц и в год, считаем, какие вложения станут безопасными, чтобы обеспечить инвестору приемлемую доходность.
В среднем объекты в регионах площадью от 8000 до 12 000 кв. м приносят около 3 млн рублей в месяц, то есть от 30 до 40 млн в год. Безопасные вложения в этом случае — от 50 до 70 млн руб. По нашему опыту, в регионах вложения в объект на этапе ремонта составляют от 5000 до 10 000 рублей на 1 кв. м. Можно вложить и больше, но это невыгодно.
В расчётах надо не забыть про операционные расходы. Если объект приносит 3 млн рублей в месяц, они должны составлять не более 1 млн. В эту цифру входят зарплаты, коммунальные платежи, обслуживание объекта недвижимости, маркетинг, текущий ремонт. Операционная рентабельность должна быть 50–70% — эти деньги в первую очередь направляются на обслуживание и возврат кредитов, возврат инвестору.
Кластер как метод критического мышления
На что ориентирована современная система образования? На повышение самостоятельности младшего школьника. Критическое мышление – это педагогическая технология, которая стимулирует интеллектуальное развитие учеников. Прием «кластер» в начальной школе – это один из его методов.
Критическое мышление проходит три стадии: вызов, осмысление, рефлексия.
Первый этап – стадия активизации. Происходит вовлечение всех учащихся в процесс. Его цель – воспроизведение уже имеющихся знаний по заданной теме, формирование ассоциативного ряда и постановка проблемных вопросов по теме. Фаза осмысления характеризуется организацией работы с информацией. Это может быть чтение материала в учебнике, обдумывание или анализ имеющихся фактов. Рефлексия – это стадия, когда полученные знания перерабатываются в ходе творческой деятельности, после чего делаются выводы.
Если взглянуть на эти три стадии с точки зрения традиционного урока, то становится очевидным, что они не являются принципиально новыми для учителей. Они присутствуют в большинстве случаев, только называются несколько иначе. «Вызов» в более привычном для учителя названии звучит как «актуализация знаний» или «введение в проблему». «Осмысление» — это не что иное, как «открытие нового знания учащимися». В свою очередь, «рефлексия» совпадает с этапом закрепления новых знаний и их первичной проверкой.
В чем же различие? Что принципиально нового несет технология «составление кластера» в начальной школе?
Элемент необычности и новизны заключается в методических приемах, ориентируемых на создание условий свободного развития каждой личности. Каждая стадия урока подразумевает использование своих методических приемов. Их существует достаточно много: кластер, инсерт, синквейн, таблица толстых и тонких вопросов, зигзаг, «шесть шляп мышления», верные и неверные утверждения и прочие.
Индексы
Возвращаясь к архитектуре системы, я бы хотел детальнее остановиться на том, как мы строили модель индексов, чтобы всё это работало корректно.
На приведённой ранее схеме это самый нижний уровень: Elasticsearch data nodes.
Индекс — это большая виртуальная сущность, состоящая из шардов Elasticsearch. Сам по себе каждый из шардов является ни чем иным, как Lucene index. А каждый Lucene index, в свою очередь, состоит и одного или более сегментов.
При проектировании мы прикидывали, что для обеспечения требования по скорости чтения на большом объёме данных нам необходимо равномерно «размазать» эти данные по дата-нодам.
Это вылилось в то, что количество шардов на индекс (с репликами) у нас должно быть строго равно количеству дата-нод. Во-первых, для того, чтобы обеспечить replication factor, равный двум (то есть мы можем потерять половину кластера). А, во-вторых, для того, чтобы запросы на чтение и запись обрабатывать, как минимум, на половине кластера.
Время хранения мы определили сперва как 30 дней.
Распределение шардов можно представить графически следующим образом:
Весь тёмно-серый прямоугольник целиком — это индекс. Левый красный квадрат в нём — это primary-шард, первый в индексе. А голубой квадрат — это replica-шард. Они находятся в разных дата-центрах.
Когда мы добавляем ещё один шард, он попадает в третий дата-центр. И, в конце концов, мы получаем вот такую структуру, которая обеспечивает возможность потери ДЦ без потери консистентности данных:
Ротацию индексов, т.е. создание нового индекса и удаление наиболее старого, мы сделали равной 48 часов (по паттерну использования индекса: по последним 48 часам ищут чаще всего).
Такой интервал ротации индексов связан со следующими причинами:
Когда на конкретную дата-ноду прилетает поисковый запрос, то, с точки зрения перформанса выгодней, когда опрашивается один шард, если его размер сопоставим с размером хипа ноды. Это позволяет держать “горячую” часть индекса в хипе и быстро к ней обращаться. Когда “горячих частей” становится много, то деградирует скорость поиска по индексу.
Когда нода начинает выполнять поисковой запрос на одном шарде, она выделяет кол-во тредов, равное количеству гипертрединговых ядер физической машины. Если поисковый запрос затрагивает большое кол-во шардов, то кол-во тредов растёт пропорционально. Это плохо отражается на скорости поиска и негативно сказывается на индексации новых данных.
Чтобы обеспечить необходимый latency поиска, мы решили использовать SSD. Для быстрой обработки запросов машины, на которых размещались эти контейнеры, должны были обладать по меньшей мере 56 ядрами. Цифра в 56 выбрана как условно-достаточная величина, определяющая количество тредов, которые будет порождать Elasticsearch в процессе работы. В Elasitcsearch многие параметры thread pool напрямую зависят от количества доступных ядер, что в свою очередь прямо влияет на необходимое кол-во нод в кластере по принципу «меньше ядер — больше нод».
В итоге у нас получилось, что в среднем шард весит где-то 20 гигабайт, и на 1 индекс приходится 360 шардов. Соответственно, если мы их ротируем раз в 48 часов, то у нас их 15 штук. Каждый индекс вмещает в себя данные за 2 дня.
Как применять метод кластера на уроках?
Итак, кластер. Примеры в начальной школе могут быть поистине разнообразными: этот прием может применяться практически на каждом уроке при изучении самых разнообразных тем.
Используя этот метод работы, можно использовать абсолютно любую форму: коллективную, индивидуальную или групповую. Она определяется поставленными целями и задачами урока, возможностями учителя и учащихся. Допустим переход из одной формы в другую.
Например, на этапе вызова каждый ученик работает в индивидуальном порядке: каждый ребенок создает собственный кластер в своей тетради. Когда начинают поступать новые знания, уже во время общей дискуссии и обсуждения, опираясь на персональные рисунки, можно составить одну общую графическую схему.
Кластер можно использовать как способ организации работы во время урока или в качестве домашней работы
Если вы задаете учащимся составить кластер дома, то помните о важности наличия у учеников определенного опыта и навыков его составления
Зоны роста
Одна из главных задач сегодня — научиться каждому кластеру представлять себя: кто такие, в чем уникальность кластеров и объяснить населению, по каким вопросам и задачам можно обращаться в эту инфраструктуру.
Еще одна задача — активнее продвигать российские кластеры на международном уровне и использовать их для развития уровня жизни для людей, которые живут на этих территориях.
При этом общее количество кластеров в России примерно 100, из них 13 в Татарстане. При этом кластеры могут «повторяться»: IT-кластер, машиностроительный кластер и т. п. Однако они все равно разные, потому что отличаются специализацией. Например, в Татарстане машиностроительный кластер строится вокруг производства грузовых машин, а в Самарской области — вокруг легковых автомобилей.
Есть и уникальные кластеры: в Смоленске создан единственный кластер по производству и переработке льна. А в Татарстане, по мнению Евгении Шамис, есть кластеры, которые пока используются не на полную мощность. Например, кластер с решениями для молодежи.
— Вы умеете работать с этой аудиторией, у вас получается много мероприятий делать — вы в целом умеете про них думать, у вас есть специалисты, которые понимают, как к этому подходить. Это тоже можно показать, потому что фактически это классный кластер, который нужно показать и в России, и в мире, — считает Шамис.
Термин
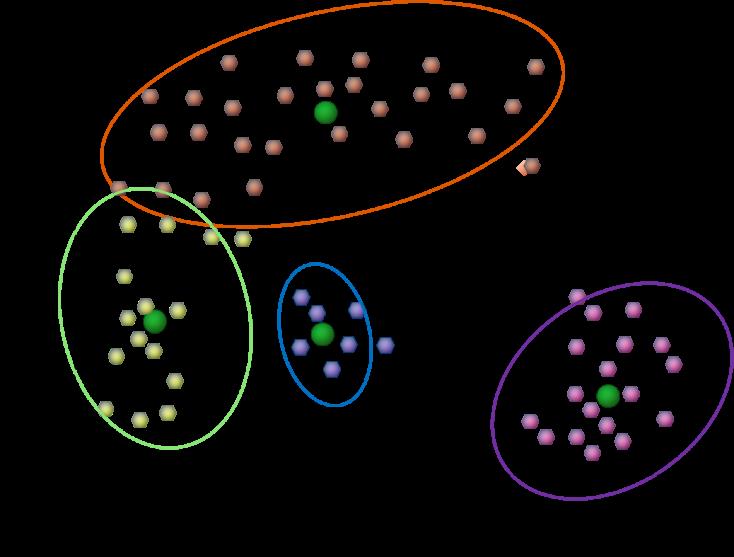
Понятие «кластер» не может быть точно определено. Это является одной из причин, по которой имеется так много методов кластеризации. Существует общий знаменатель: группа объектов данных. Однако всевозможные исследователи используют разные модели. И каждое из этих использований методов кластеризации включает в себя различные данные. Понятия найденного всевозможными алгоритмами существенно различается по его свойствам.
Использование метода кластеризации является ключом к пониманию отличий между инструкциями. Типичные кластерные модели включают в себя:
- Центроид s. Это, например, когда кластеризация методом к-средних представляет каждый кластер с одним средним вектором.
- Модель связности s. Это уже, например, иерархическая кластеризация, которая строит модели на основе дистанционной связности.
- Модель распределения s. В данном случае кластеры моделируются с использованием метода кластеризации для формирования метапредметных статистических распределений. Таких как многомерное нормальное разделение, которое применимо для алгоритма максимизации ожидания.
- Модель плотности s. Это, например, DBSCAN (алгоритм пространственной кластеризации с присутствием шума) и OPTICS (точки заказа для определения структуры), которые определяют группы как связанные плотные области в пространстве данных.
- Модель подпространства с. В biclustering (также известный как со-кластеризация или два режима) группы моделируются с обоими элементами и с соответствующими атрибутами.
- Модель s. Некоторые алгоритмы не дают уточненную связь для их метода кластеризации для формирования метапредметных результатов и просто обеспечивают группировку информации.
- Модель на основе графа s. Клик, то есть подмножество узлов, такой, что каждые два соединения в реберной части можно рассматривать как прототип формы кластера. Ослабление полного требования известны как квазиклики. Точно такое же название представлено в алгоритме кластеризации HCS.
- Нейронные модели s. Наиболее известной сетью без надзора является самоорганизующаяся карта. И именно эти модели обычно можно охарактеризовать как аналогичные одному или нескольким из вышеуказанных методов кластеризации для формирования метапредметных результатов. Включает он в себя подпространственные системы тогда, когда нейронные сети реализуют необходимую форму анализа главных или независимых компонентов.
Данный термин – это, по сути, комплект таких групп, которые обычно содержат все объекты в наборе методов кластеризации данных. Кроме того, он может указывать отношения кластеров друг к другу, например, иерархию систем, встроенных друг в друга. Группировка может быть разделена на следующие аспекты:
- Жесткий центроидный метод кластеризации. Здесь каждый объект принадлежит группе или находится вне ее.
- Мягкая или нечеткая система. В данном пункте уже каждый объект в определенной степени принадлежит всякому кластеру. Называется он также методом нечеткой кластеризации c-средних.
И также возможны более тонкие различия. Например:
- Строгая секционирующая кластеризация. Здесь каждый объект принадлежит ровно одной группе.
- Строгая секционирующая кластеризация с выбросами. В данном случае, объекты также могут не принадлежать ни к одному кластеру и считаться ненужными.
- Перекрывающаяся кластеризация (также альтернативная, с несколькими представлениями). Здесь объекты могут принадлежать более чем к одному ответвлению. Как правило, с участием твердых кластеров.
- Иерархические методы кластеризации. Объекты, принадлежащие дочерней группе, также принадлежат родительской подсистеме.
- Формирования подпространства. Хотя они и похожи на кластеры с перекрытием, внутри уникально определенной системы взаимные группы не должны загораживаться.
Существуют ли какие-либо принципы составления «грозди»?
Кластер по истории или какой-либо другой дисциплине можно оформить в виде модели планеты со своими спутниками или в виде грозди.
Ключевое понятие, мысль располагается по центру, далее, по сторонам от нее, обозначаются крупные смысловые части, которые соединяются с центральной «планетой» прямыми линиями. Это могут быть предложения, словосочетания или слова, которые выражают факты, мысли, ассоциации или образы, касающиеся темы.
Можно разделить лист на определенное количество секторов, которые будут иметь общую часть в центре — это ключевое понятие и блоки, связанные с ним.
Кластер – примеры правильной конкретизации, систематизации фактов, которые содержатся в изучаемом материале. Так, вокруг «спутников» уже существующей «планеты» появляются еще меньшие спутники, менее значительные единицы информации, которые более полно раскрывают тему и расширяют логические связи.
Внутренняя отметка
Когда результат кластеризации оценивается на основе данных, которые были сами кластеризованы, это называется данным термином. Эти методы обычно присваивают лучший результат алгоритму, который создает группы с высоким сходством внутри и низким между группами. Одним из недостатков использования внутренних критериев в оценке кластера является то, что высокие отметки необязательно приводят к эффективным приложениям для поиска информации. Кроме того, этот балл смещен в сторону алгоритмов, которые используют ту же модель. Например, кластеризация k-средних естественным образом оптимизирует расстояния до объектов, а внутренний критерий, основанный на нем, вероятно, будет переоценивать результирующую группировку.
Поэтому меры такой оценки лучше всего подходят для того, чтобы получить представление о ситуациях, когда один алгоритм работает лучше, чем другой. Но это не означает, что каждая информация дает более достоверные результаты, чем иная. Срок действия, измеряемый таким индексом, зависит от утверждения о том, что структура существует в наборе данных. Алгоритм, разработанный для некоторых типов, не имеет шансов, если комплект содержит радикально иной состав или если оценка измеряет различные критерий. Например, кластеризация k-средних может найти только выпуклые кластеры, а многие индексы оценки предполагают тот же самый формат. В наборе данных с невыпуклыми моделями нецелесообразно использование k-средних и типичных критериев оценки.
Кластеризация на основе соединений

Данное объединение также известно по такому названию, как иерархическая модель. Она основана на типичной идее о том, что объекты в большей степени связаны с соседними частями, чем с теми, которые находятся намного дальше. Эти алгоритмы соединяют предметы, образуя различные кластеры, в зависимости от их расстояния. Группа может быть описана в основном максимальной дистанцией, которая необходима для соединения различных частей кластера. На всевозможных расстояниях будут образовываться другие группы, которые можно представить с помощью дендрограммы. Это объясняет, откуда происходит общее название «иерархическая кластеризация». То есть эти алгоритмы не обеспечивают единого разделения набора данных, а вместо этого предоставляют обширный порядок подчинения. Именно благодаря ему происходит слив друг с другом на определенных расстояниях. В дендрограмме ось Y обозначает дистанцию, на которой кластеры объединяются. А объекты располагаются вдоль прямой X так, что группы не смешиваются.
Кластеризация на основе соединений — это целое семейство методов, которые отличаются способом вычисления расстояний. Помимо обычного выбора функций дистанции пользователю также необходимо определиться с критерием связи. Так как кластер состоит из нескольких объектов, есть множество вариантов для его вычисления. Популярный выбор известен как однорычажная группировка, именно это метод полной связи, который содержит UPGMA или WPGMA (невзвешенный или взвешенный ансамбль пар со средним арифметическим, также известный как кластеризация средней связи). Кроме того, иерархическая система может быть агломерационной (начиная с отдельных элементов и объединяя их в группы) или делительной (начиная с полного набора данных и разбивая его на разделы).
Кластеризация на основе плотности
В данном примере группы в основном определяются как области с более высокой непроницаемостью, чем остальная часть набора данных. Объекты в этих редких частях, которые необходимы для разделения всех компонентов, обычно считаются шумом и пограничными точками.
Наиболее популярным методом кластеризации на основе плотности является DBSCAN (алгоритм пространственной кластеризации с присутствием шума). В отличие от многих новых способов он имеет четко определенную кластерную составляющую, называемую «достижимость плотности». Подобно кластеризации на основе связей, она основана на точках соединения в пределах определенных порогов расстояния. Однако такой метод собирает только те пункты, которые удовлетворяют критерию плотности. В исходном варианте, определенном как минимальное количество других объектов в этом радиусе, кластер состоит из всех предметов, связанных плотностью (которые могут образовывать группу произвольной формы, в отличие от многих других методов), а также всех объектов, которые находятся в пределах допустимого диапазона.
Другим интересным свойством DBSCAN является то, что его сложность довольно низкая — он требует линейного количества запросов диапазона к базе данных. А также необычность заключается в том, что он обнаружит, по существу, те же самые результаты (это является детерминированным для основных и шумовых точек, но не для граничных элементов) в каждом прогоне. Поэтому нет никакой необходимости запускать его несколько раз.
Основной недостаток DBSCAN и OPTICS заключается в том, что они ожидают некоторого падения плотности для обнаружения границ кластера. Например, в наборах данных с перекрывающимися распределениями Гаусса — распространенный случай использования искусственных объектов — границы кластеров, создаваемые этими алгоритмами, часто выглядят произвольно. Происходит это, поскольку плотность групп непрерывно уменьшается. А в наборе данных, состоящем из смесей гауссианов, эти алгоритмы почти всегда превосходят такие методы, как EM-кластеризация, которые способны точно моделировать системы такого типа.
Среднее смещение — это кластерный подход, при котором каждый объект перемещается в самую плотную область в окрестности на основе оценки всего ядра. В конце концов, объекты сходятся к локальным максимумам непроницаемости. Подобно кластеризации методом к-средних, эти «аттракторы плотности» могут служить представителями для набора данных. Но среднее смещение может обнаруживать кластеры произвольной формы, аналогичные DBSCAN. Из-за дорогой итеративной процедуры и оценки плотности среднее перемещение обычно медленнее, чем DBSCAN или k-Means. Кроме того, применимость алгоритма типичного сдвига к многомерным данным затруднена из-за неравномерного поведения оценки плотности ядра, что приводит к чрезмерной фрагментации хвостов кластеров.